Statistic dan probabilitas
Statistic
dan probabilitas
Oleh
: Dr. Siswantoro
PERTEMUAN-1
PENGERTIAN STATISTIK
A. PENGERTIAN
STATISTIK
Sudjana (2004,
dalam Riduwan dan Sunarto, 2007) mendefinisikan statistika sebagai pengetahuan
yang berhubungan dengan cara-cara pengumpulan fakta, pengolahan serta pembuatan
keputusan yang cukup beralasan berdasarkan fakta dan analisa yang dilakukan.
Sementara statistic dipakai untuk menyatakan kumpulan fakta, umumnya berbentuk
angka yang disusun dalam tabel atau diagram yang melukiskan atau menggambarkan
suatu persoalan.
Lebih lanjut
Sudjana (2004, dalam Riduwan dan Sunarto, 2007) menyatakan statistika adalah
ilmu terdiri dari teori dan metode yang merupakan cabang dari matematika
terapan dan membicarakan tentang : bagaimana mengumpulkan data, bagaimana
meringkas data, mengolah dan menyajikan data, bagaimana menarik kesimpulan dari
hasil analisis, bagaimana menentukan keputusan dalam batas-batas resiko
tertentu berdasarkan strategi yang ada.
Singgih Santoso
(2002) menyatakan, pada prinsipnya statistic diartikan sebagai kegiatan untuk
mengumpulkan data, meringkas/menyajikan data, menganalisa data dengan metode
tertentu, dan menginterpretasikan hasil analisis tersebut.
Dalam kaitannya
untuk menyelesaikan masalah, pendekatan statistic terbagi dua yaitu pendekatan
statistic dalam arti sempit dan luas. Dalam arti sempit (statistic deskriptif),
statistika yang hanya mendeskripsikan tentang data yang dijadikan dalam bentuk
tabel, diagram, pengukuran rata-rata, simpangan baku, dan seterusnya tanpa
perlu menggunakan signifikansi atau tidak bermaksud membuat generalisasi.
Sementara dalam
arti luas (statistic inferensi/induktif) adalah alat pengumpul data, pengolah
data, menarik kesimpulan, membuat tindakan berdasarkan analisis data yang
dikumpulkan dan hasilnya dimanfaatkan / digeneralisasi untuk populasi.
Bidang keilmuan
statistika adalah sekumpulan metode untuk memperoleh dan menganalisa data dalam
pengambilan suatu kesimpulan. Meski merupakan cabang ilmu matematika,
statistika memiliki perbedaan mendasar pada logikanya. Jika matematika
menggunakan logika deduktif, sementara statistic menggunakan logika induktif.
Logika statistika,
dengan demikian sering disebut dengan logika induktif yang tidak memberikan
kepastian namun member tingkat peluang bahwa untuk premis-premis tertentu dapat
ditarik kesimpulan, dan kesimpulannya mungkin benar mungkin juga tidak. Langkah
yang ditempuh dalam logika statistika adalah :
1.
Observasi dan eksperimen
2.
Munculnya hipotesis ilmiah
3.
Verifikasi dan pengukuhan dan berakhir pada
4.
Sebuah teori dan hokum ilmiah (Cecep Sumarna, 2004:98)
B. LANDASAN KERJA
STATISTIK
Menurut Sutrisno
Hadi (dalam Riduwan dan Sunarto, 2007) ada tiga jenis landasan kerja statistic
meliputi :
1.
Variasi. Didasarkan atas kenyataan bahwa seorang peneliti
atau penyelidik selalu menghadapi persoalan dan gejala yang bermacam-macam
(variasi) baik dalam bentuk tingkatan dan jenisnya
2.
Reduksi, Hanya sebagian dan seluruh kejadian yang berhak
diteliti (sampling)
3.
Generalisasi. Sekalipun penelitian dilakukan terhadap
sebagain atau seluruh kejadian yang hendak diteliti, namun kesimpulan dan
penelitian ini akan diperuntukkan bagi keseluruhan kejadian atau gejala yang
diambil.
C. KARAKTERISTIK
STATISTIK
Riduwan dan Sunarto
(2007:5-6) menjelaskan beberapa karakteristik pokok statistic meliputi :
1. Statistik
bekerja dengan angka
Pertama, angka
statistic sebagai jumlah atau frekuensi dan angka statistic sebagai nilai atau
harga. Pengertian ini mengandung arti bahwa data statistic adalah data
kuantitatif. Misalnya, jumlah kecelakaan yang terjadi dalam satu tahun, jumlah
tersangka koruptor yang diproses di KPK tahun 2009, jumlah siswa SD Jakarta
tahun 2009, Jumlah siswa yang lulus UAN 2010, dan seterusnya. Angka-angka ini
menyatakan nilai atau harga sesuatu
Kedua, Angka
statistic sebagai nilai mempunyai arti data kualitatif yang diwujudkan dalam
angka. Contoh : nilai IQ, mutu pengajaran guru, metode pengajaran, nilai
kepuasan, dan seterusnya,
2. Statistik
bersifat Objektf
Statistik bekerja
dengan angka sehingga mempunyai sifat objektif, artinya angka statistic dapat
digunakan sebagai alat pencari fakta, pengungkapan kenyataan yang ada dan
memberikan keterangan yang benar, kemudian menentukan kebijakan sesuai fakta
dan temuannya yang diungkapkan apa adanya.
3. Statistik
bersifat Universal
Statistik tidak
hanya digunakan dalam salah satu disiplin ilmu saja, tetapi dapat digunakan
secara umum dalam berbagai bentuk disiplin ilmu pengetahuan dengan penuh
keyakinan.
D. MANFAAT DAN
KEGUNAAN STATISTIK
Statistik dapat
digunakan sebagai alat (Riduwan dan Sunarto, 2007) :
1. Komunikasi.
Adalah sebagai penghubungan beberapa pihak yang menghasilkan data statistic
atau berupa analisis statistic sehingga beberapa pihak tersebut akan dapat
mengambil keputusan melalui informasi tersebut.
2. Deskripsi.
Merupakan penyajian data dan mengilustrasikan data, misalnya mengukur tingkat
kelulusan siswa, laporan keuangan, tingkat inflasi, jumlah penduduk, dan
seterusnya
3. Regresi. Adalah
meramalkan pengaruh data yang satu dengan data yang lainnya dan untuk
menghadapi gejala-gejala yang akan datang
4. Korelasi. Untuk
mencari kuatnya atau besarnya hubungan data dalam suatu peneltian
5. Komparasi yaitu
membandingkan data dua kelompok atau lebih.
PERTEMUAN-2
PENGERTIAN SPSS
SPSS
adalah sebuah program komputer yang digunakan untuk membuat analisis
statistika. SPSS dipublikasikan oleh SPSS Inc.
SPSS
(Statistical Package for the
Social Sciences atau
Paket Statistik untuk Ilmu Sosial) versi pertama dirilis pada tahun 1968,
diciptakan oleh Norman Nie, seorang
lulusan Fakultas Ilmu Politik dari Stanford University, yang sekarang menjadi
Profesor Peneliti Fakultas Ilmu Politik di Stanford dan Profesor Emeritus Ilmu
Politik di University of Chicago. SPSS adalah salah satu program yang paling
banyak digunakan untuk analisis statistika ilmu sosial. SPSS digunakan oleh
peneliti pasar, peneliti kesehatan, perusahaan survei, pemerintah, peneliti
pendidikan, organisasi pemasaran, dan sebagainya. Selain analisis statistika, manajemen
data (seleksi kasus, penajaman file, pembuatan data turunan) dan dokumentasi
data (kamus metadata ikut dimasukkan bersama data) juga merupakan fitur-fitur
dari software dasar SPSS.
Statistik
yang termasuk software dasar SPSS:
·
Statistik Deskriptif: Tabulasi Silang,
Frekuensi, Deskripsi, Penelusuran, Statistik Deskripsi Rasio
·
Statistik Bivariat: Rata-rata, t-test,
ANOVA, Korelasi (bivariat, parsial, jarak), Nonparametric tests
·
Prediksi Hasil Numerik: Regresi Linear
·
Prediksi untuk mengidentivikasi kelompok:
Analisis Faktor, Analisis Cluster (two-step, K-means, hierarkis), Diskriminan.
Berbagai
fitur dalam SPSS dapat diakses melalui menu pull-down atau dapat diprogram
dengan bahasa perintah sintaks proprietary 4GL. Pemrograman perintah sintaks
memiliki keuntungan di bidang reproduktivitas serta pengendalian manipulasi
data kompleks dan analisis. Perhubungan menu pull-down juga menghasilkan
sintaks perintah, walaupun pengaturan awalnya harus diubah terlebih dahulu agar
sintaks dapat dilihat oleh user. Program dapat berjalan secara interaktif, atau
tanpa pengendalian menggunakan Fasilitas Kerja Produksi. Sebagai tambahan,
bahasa makro juga dapat digunakan untuk menulis perintah subrutin dan ekstensi
program Python dapat mengakses informasi di dalam kamus data dan data, kemudian
secara dinamis membuat program perintah sintaks.
Ekstensi
program Phyton, yang diperkenalkan pada SPSS 14, menggantikan skrip SAX Basic
yang kurang fungsional, walaupun SAX Basic juga masih dapat digunakan. Ekstensi
Phyton menyebabkan SPSS dapat menjalankan statistik mana pun dalam paket free
software R. Sejak versi 14 dan seterusnya, SPSS dapat diatur secara eksternal
melalui Phyton pada program VB.NET menggunakan
“plug-ins” yang telah disediakan.
SPSS
meletakkan batasan-batasan pada struktur file internal, tipe data, pengolahan
data dan pencocokan file, yang memudahkan pemrograman. SPSS datasets memiliki
struktur tabel 2 dimensi dimana bagian baris menunjukkan kasus-kasus (seperti
pribadi atau rumah tangga) dan bagian kolom menampilkan ukuran-ukuran (seperti
umur, jenis kelamin, pendapatan rumah tangga). Hanya 2 tipe data yang
digambarkan : numerik dan teks (string). Seluruh pengolahan data dilakukan
berurutan kasus per kasus melalui file. File dapat dipasangkan satu per satu
atau satu-banyak, tapi tidak dapat banyak per banyak.
User
interface grafis memiliki 2 jenis tampilan yang dapat dipilih dengan cara
meng-klik salah satu dari dua tombol di bagian bawah kiri dari window SPSS.
Tampilan ‘Data View’ menampilkan tampilan spreadsheet dari kasus-kasus (baris)
dan variabel (kolom). Tampilan ‘Variable View’ menampilkan kamus metadata di
mana setiap baris mewakili sebuah variabel dan menampilkan nama variabel, label
variabel, label nilai, lebar cetakan, tipe pengukuran dan variasi dari
karakteristik-karakteristik lainnya. Sel-sel di kedua tampilan dapat diedit
secara manual, memungkinkan pengaturan struktur file dan pemasukan data tanpa
harus menggunakan sintaks perintah. Hal ini cukup untuk dataset-dataset kecil.
Dataset yang lebih besar, seperti survei statistik, lebih sering dibuat
menggunakan software data entry, atau dimasukkan selama computer-assisted
personal interviewing, dengan pemindaian dan menggunakan software pengenalan
karakter optikal, atau dengan pengambilan langsung dari kuesioner online.
Dataset-dataset ini kemudian dimasukkan ke dalam SPSS.
SPSS
dapat membaca dan menulis data dari file teks ASCII (termasuk file hierarkis),
paket statistik lainnya, spreadsheets dan database. SPSS dapat membaca dan
menulis ke dalam tabel database eksternal relasional melalui ODBC dan SQL.
Output
statistik memiliki format file proprietary (file *.spo, men-support tabel
poros) yang mana, sebagai tambahan atas penampil dalam paket, disediakan
pembaca stand-alone. Output proprietary dapat diubah ke dalam bentuk teks atau
Microsoft Word. Selain itu, output dapat dibaca sebagai data (menggunakan
perintah OMS), sebagai teks, teks dengan pembatasan tabulasi, HTML, XML,
dataset SPSS atau pilihan format image grafis (JPEG, PNG, BMP, dan EMP).
Modul-modul
Add-on modules menyediakan kapabiliti tambahan. Modul-modul yang tersedia,
antara lain :
·
SPSS Programmability Extension (ditambahkan
pada versi 14). Memungkinkan pemrograman Phyton untuk mengontrol SPSS.
·
SPSS Validation Data (ditambahkan pada
versi 14). Memungkinkan pemrograman pengecekan logistik dan pelaporan
nilai-nilai mencurigakan.
·
SPSS Regression Models – Regresi logistik,
regresi ordinal, regresi logistik multinomial, dan model campuran (multilevel
models).
·
SPSS Advanced Models – GLM yang bervariasi
dan ukuran-ukuran yang diulang (dihapuskan dari basis sistem sejak versi 14).
·
SPSS Classification Trees. Membuat diagram
klasifikasi dan keputusan untuk mengidentifikasi kelompok dan memprediksi
perilaku.
·
SPSS Tables. Memungkinkan kontrol
user-defined atas output laporan.
·
SPSS Exact Tests. Memungkinkan tes
statistik atas sample kecil.
·
SPSS Categories
·
SPSS Trends
·
SPSS Conjoint
·
SPSS Missing Value Analysis. Imputasi
simpel berbasis regresi.
·
SPSS Map
·
SPSS Complex Samples (ditambahkan pada
Versi 12). Diatur untuk stratifikasi dan pengelompokkan serta pilihan pemilihan
sample lainnya.
PERTEMUAN-3
Probabilitas
3.1. Pengertian
Probabilitas
Dalam kehidupan sehari-hari kita sering dihadapkan dengan
beberapa pilihan yang harus kita tentukan memilih yang mana. Biasanya kita
dihadapkan dengan kemungkinan-kemungkinan suatu kejadian yang mungkin terjadi
dan kita harus pintar-pintar mengambil sikap jika menemukan keadaan seperti
ini, misalkan saja pada saat kita ingin bepergian, kita melihat langit terlihat
mendung. Dalam keadaaan ini kita dihadapkan antara 2 permasalahan, yaitu
kemungkinan terjadinya hujan serta kemungkinan langit hanya mendung saja dan
tidak akan turunnya hujan. Statistic yang membantu permasalahan dalam hal ini
adalah probabilitas.
Probabilitas didifinisikan sebagai peluang atau
kemungkinan suatu kejadian, suatu ukuran tentang kemungkinan atau derajat
ketidakpastian suatu peristiwa (event) yang akan terjadi di masa
mendatang. Rentangan probabilitas antara 0 sampai dengan 1. Jika kita
mengatakan probabilitas sebuah peristiwa adalah 0, maka peristiwa tersebut
tidak mungkin terjadi. Dan jika kita mengatakan bahwa probabilitas sebuah
peristiwa adalah 1 maka peristiwa tersebut pasti terjadi. Serta jumlah
antara peluang suatu kejadian yang mungkin terjadi dan peluang suatu kejadian
yang mungkin tidak terjadi adalah satu, jika kejadian tersebut hanya memiliki 2
kemungkinan kejadian yang mungkin akan terjadi.
Contoh
; Ketika doni ingin pergi kerumah temannya, dia melihat langit dalam keadaan
mendung, awan berubah warna menjadi gelap, angin lebih kencang dari biasanya
seta sinar matahari tidak seterang biasanya.
Bagaimanakah
tindakan Doni sebaiknya?
Ketika
Doni melihat keadaan seperti itu, maka sejenak dia berpikir untuk membatalkan
niatnya pergi kerumah temannya. Ini dikarenakan dia beripotesis bahwa sebentar
lagi akan turunya hujan dan kecil kemungkinan bahwa hari ini akan tidak hujan,
mengingat gejala-gejala alam yang mulai nampak.
Probabilitas
dalam cerita tadi adalah peluang kemungkinan turunnya hujan dan peluang tidak
turunnya hujan.
3.2. Manfaat
Probabilitas Dalam Penelitian
Manfaat probabilitas dalam kehidupan sehari-hari adalah membantu kita dalam
mengambil suatu keputusan, serta meramalkan kejadian yang mungkin terjadi. Jika
kita tinjau pada saat kita melakukan penelitian, probabilitas memiliki beberapa
fungsi antara lain;
Membantu
peneliti dalam pengambilan keputusan yang lebih tepat. Pengambilan keputusan
yang lebih tepat dimagsudkan tidak ada keputusan yang sudah pasti karena
kehidupan mendatang tidak ada yang pasti kita ketahui dari sekarang,
karena informasi yang didapat tidaklah sempurna.
Dengan
teori probabilitas kita dapat menarik kesimpulan secara tepat atas hipotesis
yang terkait tentang karakteristik populasi.
Menarik
kesimpulan secara tepat atas hipotesis (perkiraan sementara yang belum teruji
kebenarannya) yang terkait tentang karakteristik populasi pada situssi ini kita
hanya mengambil atau menarik kesimpulan dari hipotesis bukan berarti kejadian
yang akan dating kita sudah ketehaui apa yang akan tertjadi.
Mengukur
derajat ketidakpastian dari analisis sampel hasil penelitian dari
suatu populasi.
Contoh:
Ketika
diadakannya sensus penduduk 2000, pemerintah mendapatkan data perbandingan
antara jumlah penduduk berjenis kelamin laki-laki berbanding jumlah penduduk
berjenis kelamin perempuan adalah memiliki perbandingan 5:6, sedangkan hasil
sensus pada tahun 2010 menunjukan hasil perbandingan jumlah penduduk berjenis
kelamin pria berbanding jumlah penduduk berjenis kelamin wanita adalah 5:7.
Maka pemerintah dapat mengambil keputusan bahwa setiap tahunnya dari tahun 2000
hingga 2010 jumlah wanita berkembang lebih pesat daripada jumlah penduduk pria.
3.3. Menghitung
Probabilitas atau Peluang Suatu Kejadian
Jika tadi kita hanya memperhatikan peluang suatu kejadian
secara kualitatip, hanya memperhatikan apakkah kejadian tersebut memiliki
peluang besar akan terjadi atau tidak. Disini kita akan membahas nilai dari
probabilitas suatu kejadian secara kuantitatip. Kita bias melihat apakah suatu
kejadian berpotensi terjadi ataukah tidak.
Misalkan kita memiliki sebuah dadu yang memiliki muka
gambar dan angka,jika koin tersebut kita lemparkan keatas secara sembarang,
maka kita memiliki 2 pilihan yang sama besar dan kuat yaitu peluang munculnya
angka dan peluang munculnya gambar. Jika kita perhatikan secara seksaama, pada
satu koin hanya terddiri dari satu muka gambar dan satu muka angka, maka
peluang munculnya angka dan gambar adalah sama kuat yaitu ½. 1 menyatakan hanya
satu dari muka pada koin yang mungkin muncul, entah itu gambar maupun angka
sedangkan 2 menyatakan banyaknya kejadian yang mungkin terjadi pada pelemparan
koin, yaitu munculnya gambar + munculnya angka.
Jika
kita berbicara tidak lagi 2 kejadian yaitu menyangkut banyak kejadian yang
mungkin terjadi, mengingat dan dari hasil pengumpulan dan penelitian data
diperoleh suatu rumus sebagai berikut. Jika terdapat N peristiwa,
dan nA dari N peristiwa tersebut membentuk kejadian
A, maka probabilitas A adalah :
Dimana : nA=
banyaknya kejadian
N=
kejadian seluruhnya/peristiwa yang mungkin terjadi
Contoh.
Suatu
mata uang logam yang masing-masing sisinya berisi gambar dan
angkadilemparkan secara bebas sebanyak 1 kali.
Berapakah
probabilitas munculnya gambar atau angka?
Jawab
:
n=1, N=2
p(gambar atau
angka)=
p(gambar
atau angka)=1/2 atau 50%
Dapat
disimpulkan peluang munculnya gambar atau angka adalah sama besar.
Contoh
2.
Berapa
peluang munculnya dadu mata satu pada satu kali pelemparan?
Jika kita tinjau pada
sebuah dadu hanya memiliki 1 buah mata dadu bermata 1, sedangkan pada dadu
terdapat 6 mata yaitu mata 1 sampai mata 6.
Maka
P(A) =
nA/N
= 1/6
Berikut merupakan aturan
dalam probabilitas
Jika
n = 0 makka peluang terjadinya suatu kejadian pada keadaan ini adalah sebesar
P(A) = 0 atau tidak mungkin terjadi.
Jika
n merupakan semua anggota N maka probabilitasnya adalah satu, atau kejadian
tersebut pasti akan terjadi
Probabilitas suatu kejadian memiliki rentangan nilai
Jika
E menyatakan bukan peristiwa E maka berlaku
HUBUNGAN ANTAR KEJADIAN
A. EXCLUSIVE EVENT
Exclusive event
merupakan 2 kejadian atau lebih jika terjadinya kejadian yang
satu mencegah terjadinya kejadian lain.
Exclusive event
biasanya dihubungkan dengan kata atau.
Jika dalam suatu
peristiwa terdiri dari k buah kejadian maka dapat dirumuskan
sebagai berikut.
P(E1 atau
E2 atau.... Ek)= P(E1)+P(E2)+…P(Ek)
B. DEPENDENT EVENT
Dependent event adalah
terjadinya suatu peristiwa merupakan syarat dari peristiwa yang lainnya.
Jika kejadian yang satu
menjadi syarat terjadinya kejadian yang
lain ditulis A|B, Kita tulis A |B untuk menyatakan peristiwa A
terjadi dengan didahului terjadinya peristiwa B. peluangnya ditulis dengan p(A
|B) dan disebut dependent probability (probabilitas bersyarat). Untuk dependent
events dihubungkan dengan kata dan, sehingga berlaku hubungan:
P(A dan B)=p(B).p (A |B)
Peluangnya ditulis dengan P (A│B) dan disebut
dependent probability
Dependent event biasanya dihubungkan dengan kata “dan”.
Contoh.
Sebuah kotak berisi
A. 10
kelereng merah,
B. 20
hijau,
C. 30
kuning.
Isi kotak diaduk dan
diambil 1 buah
kelereng
secara acak
jika
pengambilan pertama sebuah kelereng berwarna hijau
(tanpa
pengembalian). Berapakah probabilitas terambilnya sebuah
kelereng
berwarna merah pada pengambilan kedua?
Merupakan peluang
kelereng warna hijau pada pengambilan pertama dan kelelereng warna merah pada
pengambilan kedua.
C. INDEPENDENT EVENT
Dua kejadian atau lebih dinamakan Independent Events,
jika kejadian yang satu tidak mempengaruhi kejadian yang lain.
Misalnya
dua kejadian A dan B. Jika terjadinya atau tidak terjadinya kejadian A tidak
mempengaruhi terjadinya kejadian B, maka A dan B disebut Independent Events.
Untuk Independent Events dihubungkan dengan kata dan, sehingga
berlaku hubungan:
P(A
dan B ) = p(A).p(B)
Untuk
berlaku k buah peristiwa berlaku:
p(E1 dan E2 dan…..dan Ek ) = p(E1 ).p(E2 )….p(Ek )
D. INCLUSIVE EVENT
Dua kejadian atau lebih dinamakan saling Inclusive events jika
terjadinya kejadian yang satu tidak mencegah terjadinya
kejadian yang lain.
Inclusive events biasanya dihubungkan dengan kata atau.
Misalnya kejadian A dan B merupakan kejadian Inclusif, berlaku hubungan
atau A atau B atau kedua-keduanya terjadi. Untuk peristiwa tersebut berlaku:
P(A+B) = P(A) + P(B) - P(A+B)
Contoh.
Jika probabilitas
kelahiran wanita dan pria adalah sama, dan probabilitas kelahiran anak berkulit
putih, kulit hitam, dan sawo matang masing-masing adalah
0,2 , 0,5 , dan 0,3. Berapakah besarnya probabilitas kelahiran anak
wanita yang berkulit putih?
Jawab.
Probabilitas kelahiran
pria dan wanita adalah sama,
sehingga p(pa
atau w)= 0,50.
Probabilitas
wanita-kulit putih=(0,50)(0,2)=0,1
P(W+P)= 0,50+0,2-0,1=0,6
3.4. Hubungan
Probabilitas Teoritik dan Probabilitas Empirik
Hubungan probabilitas
teoritik dengan probabilitas empirik dapat dijelaskan melalui contoh dari
pelemparan sebuah mata uang logam yang masih baik :
A = angka
G = gambar
Probabilitas
teoritik
Kemungkinan/
probabilitas yang diperoleh dengan menggunakan cara-cara yang berlainan serta
asumsi bahwa semua cara yang mungkin akan terjadi atas dasar kemungkinan yang
sama (equally likely basis).
Penggunaannya
Suatu
koin (uang logam)
DILEMPAR
1 KALI:
P(A)=0,50(50%)
P(G)=
0,50(50%)
DIILEMPAR
10 KALI:
P(A)=
0,50X10 kali=5 kali
P(G)=
0,50X10 kali=5 kali
Contoh.
Dalam
permainan ini standar kartu 52 dek kartu remi yang digunakan.
Dalam
rangka untuk menang Anda harus memilih "kartu wajah."
Berapa
probabilitas bahwa Anda akan memenangkan permainan ini?
JAWAB:
Secara
teori:
Setiap
kartu di dek memiliki kesempatan yang sama untuk terambil.
Ada
12 wajah kartu (kartu menang) di geladak.
Probabilitas
Empirik.
Kemungkinan
tentang terjadinya suatu peristiwa yang dihitung atas dasar
pengalaman-pengalaman atau percobaan-percobaan tentang apa yang terjadi pada
saat-saat yang sama di masa yang lalu atau atas dasar catatan statistik.
Karena
dalam menentukan probabilitas empiris Anda benar-benar melakukan percobaan,
kadang-kadang probabilitas empirik disebut:
"eksperimental probabilitas."
"eksperimental probabilitas."
Pada
kenyataannya sangat jarang terjadi demikian, karena ada kemungkinan muncul jumlah
angka atau gambar yang bervariasi dalam 10 kali pelemparan.
Kemungkinannya
tidak hanya berkisar antara 5G dan 5A, namun bisa saja kemungkinanmunculnya
angka dan gambar adalah 3G dan 7A, 4G dan 6A, dan lainnya.
Sebagai
contoh, suatu produsen radio, produksi 1000 buah radionya diuji secara acak.
Setelah pengujian, mereka menemukan 15 dari 1000 radio tersebut cacat.
Kita dapat dengan mudah menentukan bahwa probabilitas empiris bahwa radio rusak akan menjadi:
Kita dapat dengan mudah menentukan bahwa probabilitas empiris bahwa radio rusak akan menjadi:
Sebagai
desimal akan menjadi 0,15 dan sebagai suatu persen itu akan menjadi
= 1,5%.
Sekarang produsen dapat menggunakan hasil ini untuk memprediksi bahwa dalam produksi 7.500 radio, 1,5% dari mereka mungkin akan rusak.
Jadi
mereka memprediksi bahwa (0,15) (7500) = 112,5 radio rusak.
3.5. Menghitung
Nilai Harap (ekspektasi) dari suatu kejadian.
Contoh:
Ani
dan Ina bertaruh dalam pelemparan muka dadu. Jika dalam pelemparan tersebut
nampak angka ganjil, maka Ani kalah dan harus membayar kepada Ina Rp 1.000,-.
Dan jika nampak angka genap, maka Ina kalah dan harus membayar kepda ani Rp
1.000,-. Peluang munculnya angka genap dan angka ganjil pada dadu masing-masing
adalah 1/2. Jadi peluang Ani untuk membayar uang kepda Ina adalah ½, dan
peluangnya untuk menang juga ½, sehingga ekspektasi taruhan itu adalah
ξ
(untuk Ani) = ½(Rp100) + ½(-Rp100) = Rp 0.
Untuk
Ina juga berlaku hal yang sama. Berarti dalam jangka waktu yang cukup lama,
dalam permainan ini Ani dan Ina masing-masing menang nol rupiah.
3.6. Permutasi
dan Combinasi
a. Permutasi
Permutasi
dapat didefinisikan sebagai usunan yang dibentuk dari anggota-anggota
suatu himpunan dengan mengambil seluruh atau sebagian anggota himpunan dan
memberi arti pada urutan (memperhatikan urutan) anggota dari masing-masing
susunan tersebut disebut permutasi yang biasanya ditulis dengan lambang huruf
P.
Permutasi
Melingkar/Keliling
Permutasi melingkar
adalah suatu permutasi yang dibuat dengan menyusun anggota-anggota suatu
himpunan secara melingkar. Dua permutasi melingkar dianggap sama bila
didapatkan dua himpunan permutasi yang sama dengan cara beranjak dari suatu
anggota tertentu dan bergerak searah jarum jam. Banyaknya permutasi yang
disusun secara melingkar adalah (n-1) !
Contoh.
Dalam tahun ajaran baru
setiap kelas dianjurkan untuk membentuk susunan pengurus kelas yang baru. Jika
hanya dipilih 1 ketua kelas, 1 wakil ketua kelas , 1 bendahara dan 1 sekertaris
dari 8 orang calon, tentukan kemungkinan yang akan terjadi.
Jawab.
Maka
aka nada 1680 kemungkinan atau cara membentuk susunan pengurus kelas yang baru
dari 8 orang calon.
b. Combinasi
Kombinasi
didefinisikan sebagai susunan-susunan yang dibentuk dari anggota-anggota suatu
himpunan dengan mengambil seluruh atau sebagian dari anggota himpunan itu tanpa
memberi arti pada urutan anggota dari masing-masing susunan tersebut disebut
kombinasi yang ditulis dengan lambang C.
Bila himpunan itu terdiri atas n anggota dan diambil sebanyak r, tentu saja r lebih kecil atau sama dengan n, maka banyaknya susunan yang dapat dibuat dengan cara kombinasi adalah :
Kombinasi ditulis juga dengan cara : C(n,r) atau Cn,r
Bila himpunan itu terdiri atas n anggota dan diambil sebanyak r, tentu saja r lebih kecil atau sama dengan n, maka banyaknya susunan yang dapat dibuat dengan cara kombinasi adalah :
Kombinasi ditulis juga dengan cara : C(n,r) atau Cn,r
Susnan
pada combinasi tidaklah memperhatikan urutan seperti pada permutasi, oleh
daripada itu combinasi n objek yang diambil dari n adalah sebagai berikut,
Contoh.
Berapa
banyaknya kemungkinan pasangan antara calon presiden dan wakil presiden jika
ada 8 buah calon.
Jawab.
Karena
ditanya pasangan, maka akan dibentuk tim yang terdiri dari 2 orang dari 8
calon, maka dapat dicari dengan cara.
Maka
hanya ada 28 kemungkinan pasangan yang akan terjadi.
PERTEMUAN-4
PENGERTIAN HIPOTESIS
80% mahasiswa
Unpar berasal dari keluarga berpendapatan menengah ke atas.
Tindakan
agresif banyak dilakukan oleh anak yang berasal dari keluarga broken
home.
Orang yang
berpendidikan tinggi relatif lebih mudah menerima perubahan.
Terjadi
peningkatan jumlah masyarakat yang hidup di bawah garis kemiskinan semenjak
dinaikkannya harga BBM
———
Contoh HIPOTESIS ASOSIATIF/KORELASIONAL:
>>> klik sini untuk perbedaan
PENGARUH & HUBUNGAN <<<
Hipotesis PENELITIAN:
Ada hubungan antara usia dan kepuasan kerja.
Hipotesis STATISTIK:
H0: ρ = 0
H1: ρ ≠ 0
PENTING:
Hipotesis statistik HANYA DIGUNAKAN jika kita mengambil sampel dari populasi,
diuji menggunakan STATISTIK INFERENSIAL, yang tujuannya untuk menguji apakah
sampel mewakili populasi atau tidak. Hipotesis statistik TIDAK WAJIB dilakukan
jika: [1] kita mengambil data dari populasi (sensus), atau [2] kita tidak ingin
melakukan generalisasi untuk membuktikan apakah sampel mewakili populasi atau
tidak.
Terdapat
hubungan positif antara kepuasan konsumen dan loyalitas konsumen.
H0: ρ ≤ 0
H0: ρ ≤ 0
H1: ρ > 0
Ada
hubungan antara tingkat kerajinan mahasiswa dan nilai yang diperoleh: semakin
rajin mahasiswa, nilai yang diperoleh juga akan semakin baik.
H0: ρ ≤ 0
H0: ρ ≤ 0
H1: ρ > 0
Ada
hubungan antara lama antrian dengan kepuasan pelanggan: semakin lama suatu
antrian, kepuasan pelanggan juga akan semakin rendah.
H0: ρ ≥ 0
H0: ρ ≥ 0
H1: ρ < 0
Catatan:
Mengapa H0 disebut hipotesis nol/null hypothesis?! Karena tanda ‘= 0’ (baca:
sama dengan nol) HARUS diletakkan pada H0. Dengan me-reject H0, maka kita akan
menerima H1, artinya: Ada hubungan/pengaruh!!! Jika kita menerima H0, besarnya
pengaruh/hubungan akan sama dengan nol. Sebagai contoh, dalam kasus regresi
sebagai berikut: Y = 1,2 + 0X, karena besarnya pengaruh β adalah sama
dengan nol, maka berapa pun nilai X yang dimasukkan, Y akan bernilai 1,2.
Tujuan
dari uji hipotesis adalah menerima H1. Untuk mengurangi kesalahan, biasakan
memulai membuat hipotesis statistik dari H1 dulu, lalu hal-hal yang belum
tercantum di H1 kita masukan menjadi H0. Sebagai contoh, jika di H1 kita
memasukkan tanda ≠, maka di H0 kita harus memasukkan =. Jika di H1 kita
memasukkan tanda >, maka di Ho kita harus memasukkan hal-hal yang belum
dijelaskan di H1, yaitu < dan =. Mudah kan?!
Banyak
kesalahan-kesalahan terjadi dengan menuliskan hipotesis statistik sebagai
berikut:
Ho: ρ >
0 // ρ < 0 // ρ > 0
H1: ρ ≤ 0 // ρ ≥ 0 // ρ < 0
Apakah
kalian tahu di mana letak kesalahannya?
———
Contoh HIPOTESIS KAUSAL:
Ada
pengaruh antara tingkat awareness dengan knowledge konsumen.
Ho: β = 0
Ho: β = 0
H1: β ≠ 0
Angka yang
bukan nol nilainya bisa positif, bisa juga negatif. Digunakan untuk
NON-DIRECTIONAL HYPOTHESES. Dengan me-reject H0, pengaruhnya mungkin positif,
mungkin juga negatif.
Perhatikan
baik-baik hipotesis berikut:
Ada
pengaruh antara kepuasan kerja dengan produktivitas karyawan.
Ho: β = 0
Ho: β = 0
H1: β ≠ 0
Dengan
me-reject H0, berarti H1 diterima: Ada pengaruh antara kepuasan kerja dengan
produktivitas karyawan, namun kita tidak tahu pengaruhnya positif atau negatif.
Jika hasil regresi memunculkan persamaan sebagai berikut: Y = 20 – 3X, maka
kita akan menerima H1 karena β = -3 ≠ 0, artinya: dengan kenaikan kepuasan
kerja sebesar 1 akan menurunkan produktivitas karyawan sebesar 3 (pengaruhnya
negatif), padahal seperti yang kita semua tahu bahwa semakin tinggi kepuasan
kerja, produktivitas karyawan juga akan meningkat (pengaruhnya positif). Apakah
hal ini benar? Bandingkan dengan hipotesis berikut:
Ada
pengaruh positif antara kepuasan kerja dengan produktivitas karyawan.
Ho: β ≤ 0
Ho: β ≤ 0
H1: β > 0
Jika kita
menggunakan DIRECTIONAL HYPOTHESES, dengan persamaan regresi yang sama: Y = 20
– 3X, kita tentu akan menerima H0 karena nilai β = -3 < 0. Itulah alasannya
kenapa saya selalu NGOTOT UNTUK MENGGUNAKAN DIRECTIONAL HYPOTHESIS.
———
Contoh HIPOTESIS PERBEDAAN:
Ada
perbedaan motivasi kerja antara pria dan wanita.
H0: μp = μw // H0: μp – μw = 0
H1: μp ≠ μw // H1: μp – μw ≠ 0
Ada
perbedaan motivasi kerja antara pria dan wanita, dimana wanita lebih
bermotivasi dalam bekerja daripada pria.
H0: μp ≥ μw // H0: μp – μw ≥ 0
H1: μp < μw // H1: μp – μw < 0
Ada
perbedaan pengaruh insentif finansial dan non finansial terhadap unjuk kerja. Insentif
finansial lebih berpengaruh terhadap peningkatan unjuk kerja pegawai
dibandingkan dengan insentif non finansial.
H0: βF ≤ βNF // H0: βF – βNF ≤ 0
H0: βF ≤ βNF // H0: βF – βNF ≤ 0
H1: βF > βNF // H1: βF – βNF > 0
PERTEMUAN KE-5
PENGERTIAN STATISTIK DESKRIPTIF

Statistika deskriptif adalah bagian dari ilmu statistika yang hanya mengolah, menyajikan data tanpa mengambil keputusan untuk populasi. Dengan kata lain hanya melihatgambaran secara umum dari data yang didapatkan.Statistika adalah ilmu yang mempelajari bagaimana merencanakan, mengumpulkan,menganalisis, menginterpretasi, dan mempresentasikan data. Singkatnya, statistika adalahilmu yang berkenaan dengan data.Iqbal Hasan (2004:185) menjelaskan : Analisis deskriptif adalah merupakan bentuk analisis data penelitian untuk menguji generalisasi hasil penelitian berdasarkan satusample. Analisa deskriptif ini dilakukan dengan pengujian hipotesis deskriptif. Hasil analisisnya adalah apakah hipotesis penelitian dapatdigeneralisasikan atau tidak. Jika hipotesis nol (H0) diterima, berarti hasil penelitian dapat digeneralisasikan. Analisisdeskriptif ini menggunakan satu variable atau lebih tapi bersifat mandiri, oleh karena ituanalisis ini tidak berbentuk perbandingan atau hubungan.Iqbal Hasan (2001:7) menjelaskan : Statistik deskriptif atau statistic deduktif adalah bagian dari statistic mempelajari cara pengumpulan data dan penyajian data sehinggamuda dipahami. Statistic deskriptif hanya berhubungan dengan hal menguraikan ataumemberikan keterangan-keterangan mengenai suatu data atau keadaan atau fenomena.Dengan kata statistic deskriptif berfungsi menerangkan keadaan, gejala, atau persoalan.Penarikan kesimpulan pada statistic deskriptif (jika ada) hanya ditujukan pada kumpulandata yang ada.
Didasarkan pada ruang lingkup
bahasannya statistik deskriptif mencakup :1. Distribusi frekuensi beserta
bagian-bagiannya seperti : a. Grafik distibusi (histogram, poligon
frekuensi, dan ogif); b. Ukuran nilai pusat (rata-rata, median, modus,
kuartil dansebagainya); c. Ukuran dispersi (jangkauan, simpangan rata-rata, variasi, simpangan baku, dan sebagianya); d. Kemencengan
dan keruncingan kurva 2. Angka indeks 3.Times series/deret waktu atau berkala
4. Korelasi dan regresi sederhanaBambang Suryoatmono (2004:18) menyatakan
Statistika Deskriptif adalah statistika yangmenggunakan data pada suatu
kelompok untuk menjelaskan atau menarik kesimpulanmengenai kelompok itu saja
• Ukuran Lokasi: mode, mean, median, dll
• Ukuran Variabilitas: varians, deviasi standar, range, dll
Ukuran Bentuk: skewness,
kurtosis, plot boksPangestu Subagyo (2003:1) menyatakan : Yang dimaksud sebagai
statistika deskriptif adalah bagian statistika mengenai pengumpulan data,
penyajian, penentuan nilai-nilaistatistika, pembuatan diagramatau gambar
mengenai sesuatu hal, disini data yangdisajikan dalam bentuk yang lebih mudah dipahami
atau dibaca.Sudjana (1996:7) menjelaskan : Fase statistika dimana hanya
berusaha melukiskan ataumengalisa kelompok yang diberikan tanpa membuat atau
menarik kesimpulan tentang populasi atau kelompok yang lebih besar dinamakan
statistika deskriptif.
Statistik
Deskriptif dapat dinyatakan dengan frekuensi, mode, dan keragaman (variability)
a. Frekuensi
(F)
Biasanya
dinyatakan dengan persentase, bentuk yang tepat dalam menampilkan data
frekuensi adalah diagram dan grafik.
Pada
sampel di bawah ini kita lihat data perolehan suara pada pemilihan walikota
kota A, dengan jumlah suara yang diperoleh bapak Mamat memimpin dengan 38,89%.

Data
ini akan lebih menarik jika disajikan dalam bentuk diagram batang (histogram)
distribusi frekuensi suara pada pemilihan walikota kota A.

b. Mode
dan Median
Mode
adalah nilai yang paling sering muncul, ia menyatakan jumlah kategori yang
paling sering muncul pada suatu kasus. Ketika anda membagikan kuesioner kepada
karyawan kantor untuk memilih apa yang paling suka mereka lakukan di waktu
luang, jika sebagian besar menjawab mendengarkan musik, maka mendengarkan musik
adalah mode. Mode cocok untuk diterapkan pada data yang bersifat nominal.
(lihat chapter tipe data statistik disini >>>)
Median
adalah nilai tengah, ia merupakan titik tengah pembagi data. Contoh berikut
dapat mendeskripsikan median yang biasa digunakan untuk data-data ordinal.

c. Mean
(M)
Mean
merupakan rataan dari skor yang diukur, menghitung mean untuk variable X dapat
menggunakan rumus:
Fosfat
yang dihasilkan dari limbah deterjen merk A, B, C, D, dan E adalah
berturut-turut 43, 42, 31,32,37, hitunglah mean;

d. Variabilitas/Dispersi
Salah
satu teknik untuk mengelompokkan data pada teknik statistik deskriptif adalah
menghitung dispersi atau variabilitas. Tiga cara menghitung variabilitas antara
lain:

Contoh
perhitungan keragaman dan standar deviasi dapat kita lihat di bawah ini:
***
berikut ini diberikan data hasil ujian statistik dasar untuk 10 mahasiswa di
perguruan tinggi LOLipop dengan data yang diberikan sebagai berikut:

***
Menghitung Nilai Rataan:
***
Menghitung Keragaman (variance):

***
Menghitung Standar Deviasi:

Menjalankan
statistik deskriptif pada SPSS dapat melalui menubar analyse –descriptive
statistic – descriptives.(yos)

PERTEMUAN KE-6
Statistik - ANOVA (ANAVA)
2.1 PENGERTIAN STATISTIK
Statistik berasal dari kata state yang artinya negara. Dalam pengertian
yang paling sederhana statistik artinya data. Dalam pengertian yang lebih luas,
statistik dapat diartikan sebagai kumpulan data dalam bentuk angka maupun bukan
angka yang disusun dalam bentuk tabel (daftar) dan atau diagram yang
menggambarkan (berkaitan) dengan suatu masalah tertentu. (skripsizone.com 2008,
p3)
Statistik adalah suatu istilah yang dipakai
untuk menyatakan kumpulan data, bilangan maupun non bilangan yang disusun dalam
tabel, diagram yang melukiskan atau menggambarkan suatu persoalan.(Universitas
Negeri Jakarta 2008,p1)
Umumnya suatu data diikuti atau dilengkapi
dengan keterangan-keterangan yang berkaitan dengan suatu peristiwa atau keadaan
tertentu. Kata statistik juga menyatakan ukuran atau karakteristik pada sampel
seperti nilai rata-rata, dan koefisien korelasi.
Berdasarkan asumsi sebaran yang
dipergunakan, metode statistika
dapat dibedakan menjadi dua bagian utama yaitu:
1.
Statistika Parametrik:
yaitu analisis yang didasarkan atas asumsi bahwa data memiliki sebaran tertentu
(diskrit atau kontinu, normal atau tidak normal) dengan parameter yang belum
diketahui. Fungsi metode statistika adalah untuk meramal parameter, melakukan
uji parameter, atau semata-mata melakukan eksplorasi berdasarkan informasi yang
ada pada data.
2.
Statistika Nonparametrik:
yaitu analisis yang tidak didasarkan atas asumsi distribusi pada data. Umumnya
teknikini dipakai untuk data dengan uKuran kecil sehingga tidak cukup kuat
untuk mengasumsikan distribusi tertentu pada data.
2.2 PENGERTIAN ANOVA
Jika banyaknya subpopulasi lebih dari dua
(tiga atau lebih), maka uji yang dapat dilakukan adalah uji ANAVA/ANOVA
(Analisis variansi/analysis of variance). Pada umumnya uji anova dibatasi pada
subpopulasi yang saling bebas yaitu subpopulasi satu dengan lainnya bukan
merupakan subpopulasi yang sama, juga bukan merupakan subpopulasi yang
berpasangan. Uji Anova dibedakan menjadi dua macam yaitu:
Anova satu arah/one-way Anova (jika hanya ada
satu pengelompokan yang menjadi
perhatian, misalnya status sosial: kaya, menengah,miskin)
Multivariate Anova yaitu Anova untuk respon
yang tidak saling bebas (multivariat). Data multivariat ini terjadi apabila
kelompok yang sama diamati untuk lebih dari dua atribut (misalnya untuk
mahasiswa dilihat nilai Tugas, Nilai Ujian Mid dan Nilai Ujian Akhir, atau satu
atribut di amati lebih dari dua kali (tekanan darah pasien pagi, siang dan
malam hari).
Tujuan
Anova : (Binus University 2008, p81)
Menguji
apakah rata-rata lebih dari dua sampel berbeda secara signifikan atau tidak.
Menguji
apakah dua buah sampel mempunyai varians populasi yang sama atau tidak.
Beberapa
asumsi yang mendasari Anova adalah :
a) Populasi
yang akan diuji berdistribusi normal.
b) Varians
dari populasi tersebut adalah sama.
c) Sampel
tidak berhubungan satu dengan yang lain.
2.3 DISTRIBUSI F
Jika uji t digunakan untuk pengujian dua sampel,
uji F atau Anova digunakan untuk
pengujian lebih dari dua sampel.
Distribusi F digunakan untuk menguji hipotesis, apakah variansi dari sebuah
populasi normal sama dengan variansi dari populasi normal lainnya. Satu
variansi sampel yang lebih besar ditempatkan pada pembilang, sehingga rasio
minimalnya adalah 1,00. Distribusi F juga digunakan untuk menguji asumsi-asumsi
bagi beberapa statistik uji.
Berdasarkan pendapat Douglas A. Lind (2005, p387-388), Distribusi F
memiliki ciri-ciri sebagai berikut:
1.
Terdapat suatu keluarga distribusi F.
Suatu anggota keluarga distribusi F di tentukan berdasarkan dua parameter :
derajat kebebasan pada pembilang dan derajat kebebasan pada penyebut.
2.
Distribusi F bersifat kontinu.
3.
Distribusi F tidak dapat bernilai negatif.
4.
Bentuknya tidak simetris.
5.
Bersifat Asimtotik (Asymptotic).
Distribusi F memberikan sebuah perangkat untuk menjalankan suatu uji
variansi dari dua populasi normal. Menentukan validasi sebuah asumsi untuk
suatu statistik uji, mula-mula kita tetap harus menentukan hipotesis nolnya.
Hipotesis nolnya adalah bahwa variansi dari suatu populasi (σ1²), sama dengan variansi dari populasi
normal lainnya (σ2²). Hipotesis alternatifnya dapat berupa perbedaan variansi
tersebut. Dalam hal ini hipotesis nolnya dan hipotesis alternatifnya adalah :
H0 : σ1² = σ2²
H1 : σ1² ≠ σ2²
PERTEMUAN KE-7
PENGERTIAN KORELASI, KORELASI SEDERHANA, BERGANDA, PARSIAL DAN RANK
SPEARMAN
PENGERTIAN KORELASI
Persoalan pengukuran, atau pengamatan hubungan antara dua peubah X dan Y, berikut ini akan kita bicarakan sesuai dengan referensi yang kami peroleh dalam beberapa literatur. Tulisan ini tentu saja tidak selengkap seperti halnya tulisan tentang Pengertian Korelasi dalam buku Statistika yang ditulis oleh, Ronald E. Walpole, Sugiono, Murray R. Spiegel, atau beberapa Statistikawan yang memang saya kagumi ke-pakar-annya. Akan tetapi setidaknya bisa dijadikan bacaan tambahan bagi mahasiswa yang ingin mengetahui lebih jauh tentang persoalan korelasi atau persoalan-persoalan lain yang berkaitan dengan hubungan antar dua peubah.
Kita tidak
akan dan bukan meramalkan nilai Y dari pengetahuan mengenai peubah bebas X
seperti dalam regresi linier. Sebagai misal, bila peubah X menyatakan besarnya
biaya yang dikeluarkan untuk membeli Pupuk dan Y adalah besarnya hasil Produksi
Padi dalam satu kali musim tanam, barangkali akan muncul pertanyaan dalam hati
kita apakah penurunan biaya yang dikeluarkan untuk membeli Pupuk juga
berpeluang besar untuk diikuti dengan penurunan hasil Produksi Padi dalam satu
musim tanam. Dalam studi empiris lain, bila X adalah harga suatu barang yang
ditawarkan dan Y adalah jumlah permintaan terhadap barang tersebut yang dibeli
oleh konsumen, maka kita membayangkan jika nilai-nilai X yang besar tentu akan
berpasangan dengan nilai-nilai Y yang kecil.
Dalam hal ini kita tentu saja mempunyai bilangan yang menyatakan proporsi keragaman total nilai-nilai peubah Y yang dapat dijelaskan oleh nilai-nilai peubah X melalui hubungan linear tersebut. Jadi misalkan suatu korelasi memiliki besaran r = 0,36 bermakna bahwa 0,36 atau 36% di antara keragaman total nilai-nilai Y dalam contoh kita, dapat dijelaskan oleh hubungan linearnya dengan nilai-nilai X.
Contoh lainnya adalah, misal koefisien korelasi sebesar 0,80 menunjukkan adanya hubungan linear yang sangat baik antara X dan Y. Karena r2 = 0,64, maka kita dapat mengatakan bahwa 64 % di antara keragaman dalam nilai-nilai Y dapat dijelaskan oleh hubungan linearnya dengan X.
Dalam hal ini kita tentu saja mempunyai bilangan yang menyatakan proporsi keragaman total nilai-nilai peubah Y yang dapat dijelaskan oleh nilai-nilai peubah X melalui hubungan linear tersebut. Jadi misalkan suatu korelasi memiliki besaran r = 0,36 bermakna bahwa 0,36 atau 36% di antara keragaman total nilai-nilai Y dalam contoh kita, dapat dijelaskan oleh hubungan linearnya dengan nilai-nilai X.
Contoh lainnya adalah, misal koefisien korelasi sebesar 0,80 menunjukkan adanya hubungan linear yang sangat baik antara X dan Y. Karena r2 = 0,64, maka kita dapat mengatakan bahwa 64 % di antara keragaman dalam nilai-nilai Y dapat dijelaskan oleh hubungan linearnya dengan X.
Besaran
koefisien korelasi contoh r merupakan sebuah nilai yang dihitung dari n
pengamatan sampel. Sampel acak berukuran n yang lain tetapi diambil dari
populasi yang sama biasanya akan menghasilkan nilai r yang berbeda pula. Dengan
demikian kita dapat memandang r sebagai suatu nilai dugaan bagi koefisien
korelasi linear yang sesungguhnya berlaku bagi seluruh anggota populasi.
Misalkan kita lambangkan koefisien korelasi populasi ini dengan ρ. Bila r dekat
dengan nol, kita cenderung menyimpulkan bahwa ρ = 0. Akan tetapi, suatu nilai
contoh r yang mendekati + 1 atau – 1 menyarankan kepada kita untuk menyimpulkan
bahwa ρ ≠ 0.
Masalahnya sekarang adalah bagaimana memperoleh suatu peng-uji-an yang akan mengatakan kepada kita kapan r akan berada cukup jauh dari suatu nilai tertentu ρo, agar kita mempunyai cukup alasan untuk menolak hipotesis nol (Ho) bahwa ρ = ρo, dan menerima alternatifnya. Hipotesis alternatif bagi H1 biasanya salah satu di antara ρ < ρo, ρ > ρo, atau ρ ≠ ρo.
Masalahnya sekarang adalah bagaimana memperoleh suatu peng-uji-an yang akan mengatakan kepada kita kapan r akan berada cukup jauh dari suatu nilai tertentu ρo, agar kita mempunyai cukup alasan untuk menolak hipotesis nol (Ho) bahwa ρ = ρo, dan menerima alternatifnya. Hipotesis alternatif bagi H1 biasanya salah satu di antara ρ < ρo, ρ > ρo, atau ρ ≠ ρo.
J Supranto, Statistika, Teori Dan Aplikasi, Penerbit
Erlangga, Jakarta, 1987.
Riduan, Dasar-dasar Statistika, Penerbit ALFABETA,
Bandung, 2005.
Ronald E. Walpole, Pengantar Statistika, Edisi ke-3,
Penerbit PT. Gramedia Pustaka Utama, Jakarta, 1992.
Suharto, Kumpulan Bahan Kuliah, Pengantar
Statistika, UM Metro, Lampung, 2007.
Murray R. Spiegel, Seri Buku Schaum, Teori dan Soal,
Statistika, Edisi Kedua. Alih Bahasa oleh Drs. I Nyoman Susila, M.Sc. dan Ellen
Gunawan, M.M., Penerbit Erlangga, 1988.
1. ANALISIS KORELASI SEDERHANA
Analisis korelasi sederhana (Bivariate Correlation)
digunakan untuk mengetahui keeratan hubungan antara dua variabel dan untuk
mengetahui arah hubungan yang terjadi. Koefisien korelasi sederhana menunjukkan
seberapa besar hubungan yang terjadi antara dua variabel. Dalam SPSS ada tiga
metode korelasi sederhana (bivariate correlation) diantaranya Pearson
Correlation, Kendall’s tau-b, dan Spearman Correlation. Pearson
Correlation digunakan untuk data berskala interval atau rasio,
sedangkan Kendall’s tau-b, dan Spearman Correlation lebih
cocok untuk data berskala ordinal.
Pada bab ini akan dibahas analisis korelasi sederhana
dengan metode Pearson atau sering disebut Product Moment
Pearson. Nilai korelasi (r) berkisar antara 1 sampai -1, nilai semakin
mendekati 1 atau -1 berarti hubungan antara dua variabel semakin kuat, sebaliknya
nilai mendekati 0 berarti hubungan antara dua variabel semakin lemah. Nilai
positif menunjukkan hubungan searah (X naik maka Y naik) dan nilai negatif
menunjukkan hubungan terbalik (X naik maka Y turun).
Menurut Sugiyono (2007) pedoman untuk memberikan interpretasi
koefisien korelasi sebagai berikut:
0,00 - 0,199 =
sangat rendah
0,20 - 0,399 =
rendah
0,40 - 0,599 =
sedang
0,60 - 0,799 =
kuat
0,80 - 1,000 =
sangat kuat
Contoh kasus:
Seorang mahasiswa bernama Andi melakukan penelitian
dengan menggunakan alat ukur skala. VITA ingin mengetahui apakah ada hubungan
antara kecerdasan dengan prestasi belajar pada siswa SMU NEGRI xxx dengan ini
VITA membuat 2 variabel yaitu kecerdasan dan prestasi belajar. Tiap-tiap
variabel dibuat beberapa butir pertanyaan dengan menggunakan skala Likert,
yaitu angka 1 = Sangat tidak setuju, 2 = Tidak setuju, 3 = Setuju dan 4 =
Sangat Setuju. Setelah membagikan skala kepada 12 responden didapatlah skor
total item-item yaitu sebagai berikut:
Tabel. Tabulasi Data (Data Fiktif)
|
Subjek
|
Kecerdasan
|
Prestasi Belajar
|
|
1
|
33
|
58
|
|
2
|
32
|
52
|
|
3
|
21
|
48
|
|
4
|
34
|
49
|
|
5
|
34
|
52
|
|
6
|
35
|
57
|
|
7
|
32
|
55
|
|
8
|
21
|
50
|
|
9
|
21
|
48
|
|
10
|
35
|
54
|
|
11
|
36
|
56
|
|
12
|
21
|
47
|
Langkah-langkah pada program SPSS
Ø Masuk program SPSS
Ø Klik variable view pada SPSS data editor
Ø Pada kolom Name ketik x, kolom Name pada
baris kedua ketik y.
Ø Pada kolom Decimals ganti menjadi 0 untuk
variabel x dan y
Ø Pada kolom Label, untuk kolom pada baris
pertama ketik Kecerdasan, untuk kolom pada baris kedua ketik Prestasi Belajar.
Ø Untuk kolom-kolom lainnya boleh dihiraukan
(isian default)
Ø Buka data view pada SPSS data editor, maka
didapat kolom variabel x dan y.
Ø Ketikkan data sesuai dengan variabelnya
Ø Klik Analyze - Correlate - Bivariate
Ø Klik variabel Kecerdasan dan masukkan ke
kotak Variables, kemudian klik variabel Prestasi Belajar dan masukkan ke kotak
yang sama (Variables).
Ø Klik OK, maka hasil output yang didapat
adalah sebagai berikut:
Tabel.
Hasil Analisis Korelasi Bivariate Pearson

Dari hasil analisis korelasi sederhana (r) didapat
korelasi antara kecerdasan dengan prestasi belajar (r) adalah 0,766. Hal ini
menunjukkan bahwa terjadi hubungan yang kuat antara kecerdasan dengan prestasi
belajar. Sedangkan arah hubungan adalah positif karena nilai r positif, berarti
semakin tinggi kecerdasan maka semakin meningkatkan prestasi belajar.
- Uji Signifikansi Koefisien
Korelasi Sederhana (Uji t)
Uji signifikansi koefisien korelasi digunakan untuk
menguji apakah hubungan yang terjadi itu berlaku untuk populasi (dapat
digeneralisasi). Misalnya dari kasus di atas populasinya adalah siswa SMU NEGRI
XXX dan sampel yang diambil dari kasus di atas adalah 12 siswa SMU NEGRI XXX,
jadi apakah hubungan yang terjadi atau kesimpulan yang diambil dapat berlaku
untuk populasi yaitu seluruh siswa SMU Negeri XXX.
Langkah-langkah pengujian sebagai berikut:
1. Menentukan Hipotesis
Ho : Tidak ada hubungan secara signifikan antara
kecerdasan dengan prestasi belajar
Ha : Ada hubungan secara signifikan antara
kecerdasan dengan prestasi belajar
2. Menentukan tingkat signifikansi
Pengujian
menggunakan uji dua sisi dengan tingkat signifikansi a = 5%. (uji
dilakukan 2 sisi karena untuk mengetahui ada atau tidaknya hubungan yang
signifikan, jika 1 sisi digunakan untuk mengetahui hubungan lebih kecil atau
lebih besar).
Tingkat signifikansi dalam hal ini berarti kita mengambil
risiko salah dalam mengambil keputusan untuk menolak hipotesa yang benar
sebanyak-banyaknya 5% (signifikansi 5% atau 0,05 adalah ukuran standar yang
sering digunakan dalam penelitian)
3. Kriteria Pengujian
Ho diterima jika Signifikansi > 0,05
Ho
ditolak jika Signifikansi < 0,05
4. Membandingkan signifikansi
Nilai signifikansi 0,004 < 0,05, maka Ho ditolak.
5. Kesimpulan
Oleh karena nilai Signifikansi (0,004 < 0,05) maka Ho
ditolak, artinya bahwa ada hubungan secara signifikan antara kecerdasan dengan
prestasi belajar. Karena koefisien korelasi nilainya positif, maka berarti
kecerdasan berhubungan positif dan signifikan terhadap pretasi belajar. Jadi
dalam kasus ini dapat disimpulkan bahwa kecerdasan berhubungan positif terhadap
prestasi belajar pada siswa SMU Negeri XXX
2. ANALISIS KOEFISIEN KORELASI LINEAR BERGANDA
Adalah indeks atau angka yang diigunakan untuk mengukur
keeratan hubungan antara 3 variabel/lebih. Koefisien korelasi berganda
dirumuskan :
Ry1.2 = 

Keterangan :
- Ry1.2
: koefisien linier 3 variabel
- ry1
: koefisien korelasi y dan X1
- ry2
: koefisien korelasi variabel y dan X2
- r1.2
: koefisien korelasi variabel X1 dan X2
dimana :
ry1 = 

ry2 = 

r1.2 =


Ry1.2 = 

Contoh Soal :
|
VARIABEL
|
RUMAH TANGGA
|
||||||
|
I
|
II
|
III
|
IV
|
V
|
VI
|
VII
|
|
|
Pengeluaran (Y)
|
3
|
5
|
6
|
7
|
4
|
6
|
9
|
|
Pendapatan (X1)
|
5
|
8
|
9
|
10
|
7
|
7
|
11
|
|
Jumlah Anggota Keluarga (X2)
|
4
|
3
|
2
|
3
|
2
|
4
|
5
|
Pertanyaan :
Carilah Nilai Koefisien Korelasinya !
Jelaskan makna hubungannya !
Penyelesaian :
|
No
|
Y
|
X1
|
X2
|
Y2
|
X12
|
X22
|
X1Y
|
X2Y
|
X1 X2
|
|
1
|
3
|
5
|
4
|
9
|
25
|
16
|
15
|
12
|
20
|
|
2
|
5
|
8
|
3
|
25
|
64
|
9
|
40
|
15
|
24
|
|
3
|
6
|
9
|
2
|
36
|
81
|
4
|
54
|
12
|
18
|
|
4
|
7
|
10
|
3
|
49
|
100
|
9
|
70
|
21
|
30
|
|
5
|
4
|
7
|
2
|
16
|
49
|
4
|
28
|
8
|
14
|
|
6
|
6
|
7
|
4
|
36
|
49
|
16
|
42
|
24
|
28
|
|
7
|
9
|
11
|
5
|
81
|
121
|
25
|
99
|
45
|
55
|
|
∑
|
40
|
57
|
23
|
252
|
489
|
83
|
348
|
137
|
189
|




Berdasarkan hasil perhitungan diperoleh nilai Korelasi (R) = 0,9686 atau 0,97.
Nilai Korelasi (R) = 0,97 bermakna bahwa hubungan kedua
variabel X (X1 dan X2) sangat kuat karena nilai R mendekati 1.
3. ANALISIS KORELASI PARSIAL
Koefisien korerasi parsial adalah indeks atau angka yang
digunakan untuk mengukur keeratan hubungan antara 2 variabel, jika variabel
lainnya konstanta, pada hubungan yang melibatkan lebih dari dua variabel.
Koefisien korelasi parsial untuk tiga variabel dirumuskan oleh :
1. Koefisien korelasi
parsial antara Y dan X1 apabila X2 konstanta.
ry1.2 =

2. Koefisien korelasi
parsial antara Y dan X2 apabila X1 konstanta
ry2.1 = 

3. Koefisien korelasi parsial
antara X1 dan X2 apabila Y konstanta
r2.1Y = 

Analisis korelasi parsial (Partial Correlation) digunakan
untuk mengetahui hubungan antara dua variabel dimana variabel lainnya yang
dianggap berpengaruh dikendalikan atau dibuat tetap (sebagai variabel kontrol).
Nilai korelasi (r) berkisar antara 1 sampai -1, nilai semakin mendekati 1 atau
-1 berarti hubungan antara dua variabel semakin kuat, sebaliknya nilai
mendekati 0 berarti hubungan antara dua variabel semakin lemah. Nilai positif
menunjukkan hubungan searah (X naik maka Y naik) dan nilai negatif menunjukkan
hubungan terbalik (X naik maka Y turun). Data yang digunakan biasanya berskala
interval atau rasio.
Menurut Sugiyono (2007) pedoman untuk memberikan
interpretasi koefisien korelasi sebagai berikut:
0,00 - 0,199 =
sangat rendah
0,20 - 0,399 =
rendah
0,40 - 0,599 =
sedang
0,60 - 0,799 =
kuat
0,80 - 1,000 =
sangat kuat
Contoh kasus:
Kita mengambil contoh pada kasus korelasi sederhana di
atas dengan menambahkan satu variabel kontrol. Seorang mahasiswa bernama Andi
melakukan penelitian dengan menggunakan alat ukur skala. Andi ingin meneliti
tentang hubungan antara kecerdasan dengan prestasi belajar jika terdapat faktor
tingkat stress pada siswa yang diduga mempengaruhi akan dikendalikan. Dengan
ini Andi membuat 2 variabel yaitu kecerdasan dan prestasi belajar dan 1 variabel
kontrol yaitu tingkat stress. Tiap-tiap variabel dibuat beberapa butir
pertanyaan dengan menggunakan skala Likert, yaitu angka 1 = Sangat tidak
setuju, 2 = Tidak setuju, 3 = Setuju dan 4 = Sangat Setuju. Setelah membagikan
skala kepada 12 responden didapatlah skor total item-item yaitu sebagai
berikut:
Tabel.
Tabulasi Data (Data Fiktif)
|
Subjek
|
Kecerdasan
|
Prestasi Belajar
|
Tingkat Stress
|
|
1
|
33
|
58
|
25
|
|
2
|
32
|
52
|
28
|
|
3
|
21
|
48
|
32
|
|
4
|
34
|
49
|
27
|
|
5
|
34
|
52
|
27
|
|
6
|
35
|
57
|
25
|
|
7
|
32
|
55
|
30
|
|
8
|
21
|
50
|
31
|
|
9
|
21
|
48
|
34
|
|
10
|
35
|
54
|
28
|
|
11
|
36
|
56
|
24
|
|
12
|
21
|
47
|
29
|
Langkah-langkah pada program SPSS
Masuk program SPSS
Klik variable view pada SPSS data editor
Pada kolom Name ketik x1, kolom Name pada
baris kedua ketik x2, kemudian kolom Name pada baris ketiga ketik y.
Pada kolom Decimals ganti menjadi 0 untuk
semua variabel
Pada kolom Label, untuk kolom pada baris
pertama ketik Kecerdasan, untuk kolom pada baris kedua Tingkat Stress, dan
kolom pada baris ketiga ketik Prestasi Belajar.
Untuk kolom-kolom lainnya boleh dihiraukan
(isian default)
Buka data view pada SPSS data editor, maka
didapat kolom variabel x1, x2 dan y.
Ketikkan data sesuai dengan variabelnya
Klik Analyze - Correlate - Partial
Klik variabel Kecerdasan dan masukkan ke
kotak Variables, kemudian klik variabel Prestasi Belajar dan masukkan ke kotak
yang sama (Variables). Klik variabel Tingkat Stres dan masukkan ke kotak
Controlling for
Klik OK, maka hasil output yang didapat
adalah sebagai berikut:
Tabel. Hasil Analisis Korelasi Parsial
- P A R T I A L C O R R E L A T I O
N C O E F F I C I E N T S -
Controlling for.. X2
X1 Y
X1 1.0000 .4356
( 0) ( 9)
P=
. P=
.181
Y .4356 1.0000
( 9) ( 0)
P=
.181 P=
.
(Coefficient / (D.F.) / 2-tailed Significance)
" . " is printed if a coefficient cannot be
computed
Dari hasil analisis korelasi parsial (ry.x1x2) didapat
korelasi antara kecerdasan dengan prestasi belajar dimana tingkat stress dikendalikan
(dibuat tetap) adalah 0,4356. Hal ini menunjukkan bahwa terjadi hubungan yang
sedang atau tidak terlalu kuat antara kecerdasan dengan prestasi belajar jika
tingkat stress tetap. Sedangkan arah hubungan adalah positif karena nilai r
positif, artinya semakin tinggi kecerdasan maka semakin meningkatkan prestasi
belajar.
- Uji Signifikansi Koefisien
Korelasi Parsial (Uji t)
Uji signifikansi koefisien korelasi parsial digunakan
untuk menguji apakah hubungan yang terjadi itu berlaku untuk populasi (dapat
digeneralisasi). Langkah-langkah pengujian sebagai berikut:
1. Menentukan Hipotesis
Ho : Tidak ada hubungan secara signifikan antara
kecerdasan dengan prestasi belajar jika tingkat stress tetap
Ha : Ada hubungan secara signifikan antara kecerdasan
dengan prestasi belajar jika tingkat stress tetap
2. Menentukan tingkat signifikansi
Pengujian
menggunakan uji dua sisi dengan tingkat signifikansi = 5%. (uji
dilakukan 2 sisi karena untuk mengetahui ada atau tidaknya hubungan yang signifikan,
jika 1 sisi digunakan untuk mengetahui hubungan lebih kecil atau lebih besar)
Tingkat signifikansi dalam hal ini berarti kita mengambil
risiko salah dalam mengambil keputusan untuk menolak hipotesa yang benar
sebanyak-banyaknya 5% (signifikansi 5% atau 0,05 adalah ukuran standar yang
sering digunakan dalam penelitian)
3. Kriteria Pengujian
Berdasar probabilitas:
Ho diterima jika P value > 0,05
Ho
ditolak jika P value < 0,05
4. Membandingkan probabilitas
Nilai P value (0,181 > 0,05) maka Ho
diterima.
8. Kesimpulan
Oleh karena nilai P value (0,181 > 0,05)
maka Ho diterima, artinya bahwa tidak ada hubungan secara signifikan antara
kecerdasan dengan prestasi belajar jika tingkat stress dibuat tetap. Hal ini
dapat berarti terdapat hubungan yang tidak signifikan, artinya hubungan
tersebut tidak dapat berlaku untuk populasi yaitu seluruh siswa SMU Negeri XXX,
tetapi hanya berlaku untuk sampel. Jadi dalam kasus ini dapat disimpulkan bahwa
kecerdasan tidak berhubungan terhadap prestasi belajar pada siswa SMU Negeri
XXX.
4. KORELASI RANK SPEARMAN
Korelasi Rank Spearman digunakan untuk mencari hubungan
atau untuk menguji signifikansi hipotesis asosiatif bila masing-masing variabel
yang dihubungkan berbentuk Ordinal.
Contoh:
Ada 10 orang responden yang diminta untuk mengisi daftar
pertanyaan tentang Motivasi dan Prestasi dalam sebuah kantor. Jumlah responden
yang diminta mengisi daftar pertanyaan itu 10 karyawan, masing-masing diberi
nomor 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. Nilai yang diberikan oleh kesepuluh
responden tentang Motivasi dan Prestasi itu diberikan pada contoh berikut. Yang
akan diketahui adalah apakah ada hubungan antara Motivasi dengan Prestasi.
Berdasarkan hal tersebut maka:
Judul penelitian adalah : Hubungan antara Motivasi dengan
Prestasi.
Variabel penelitiannya adalah : nilai jawaban dari 10
responden tentang Motivasi (Xi) dan Prestasi (Yi)
Rumusan masalah: apakah ada hubungan antara variabel
Motivasi dan Prestasi?
Hipotesis:
Ho: tidak ada hubungan antara variabel Motivasi dan
Prestasi.
Ha: ada hubungan antara variabel Motivasi dan Prestasi
5. Kriteria Pengujian Hipotesis
Ho ditolak bila
harga ρ hitung > dari ρ tabel
Ho diterima bila
harga ρ hitung ≤ dari ρ tabel
Penyajian data
Jawaban responden yang telah terkumpul ditunjukkan
pada Tabel 1 berikut ini:
Tabel 1. Nilai Motivasi dan Prestasi
|
Nomor responden
|
Jumlah Skor
|
Jumlah skor
|
|
1
|
9
|
8
|
|
2
|
6
|
7
|
|
3
|
5
|
6
|
|
4
|
7
|
8
|
|
5
|
4
|
5
|
|
6
|
3
|
4
|
|
7
|
2
|
2
|
|
8
|
8
|
9
|
|
9
|
7
|
8
|
|
10
|
6
|
6
|
6. Perhitungan untuk pengujian Hipotesis
Data tersebut diperoleh dari sumber yang berbeda yaitu
Motivasi (Xi) dan Prestasi (Yi). Karena sumber datanya berbeda dan berbentuk
ordinal, maka untuk menganalisisnya digunakan Korelasi Rank yang rumusnya
adalah:
ρ = 1 – ( 6Σbi 2 : N (
N2 – 1 )
ρ
= koefisien korelasi Spearman Rank
di =
beda antara dua pengamatan berpasangan
N
= total pengamatan
Korelasi Spearman rank bekerja dengan data ordinal.
Karena jawaban responden merupakan data ordinal, maka data tersebut diubah
terlebih dahulu dari data ordinal dalam bentuk ranking yang caranya dapat
dilihat dalam Tabel 2.
Bila terdapat nilai yang sama, maka cara membuat
peringkatnya adalah: Misalnya pada Xi nilai 9 adalah peringkat ke 1, nilai 8 pada
peringkat ke 2, selanjutnya disini ada nilai 7 jumlahnya dua. Mestinya
peringatnya kalau diurutkan adalah peringkat 3 dan 4. tetapi karena nilainya
sama, maka peringkatnya dibagi dua yaitu: (3 + 4) : 2 = 3,5. akhirnya dua nilai
7 pada Xi masing-masing diberi peringkat 3,5. Selanjutnya pada Yi disana ada
nilai 8 jumlahnya tiga. Mestinya peringkatnya adalah 2, 3 dan 4. Tetapi karena
nilainya sama maka peringkatnya dibagi tiga yaitu: (2 + 3 + 4) : 3 = 3. Jadi
nilai 8 yang jumlahnya tiga masing-masing diberi peringkat 3 pada kolom Yi.
Selanjutnya nilai 7 diberi peringkat setelah peringkat 4 yaitu peringkat 5.
Lanjutkan saja…..
Tabel 2. Tabel penolong untuk menghitung koefisien
korelasi Spearman Rank.
|
Nomor Responden
|
Nilai Motivasi Resp. I (Xi)
|
Nilai Prestasi dari Resp. II
(Yi)
|
Peringkat (Xi)
|
Peringkat (Yi)
|
bi
|
bi2
|
|
1
|
9
|
8
|
1
|
3
|
-2
|
4
|
|
2
|
6
|
7
|
5,5
|
5
|
0,5
|
0,25
|
|
3
|
5
|
6
|
7
|
6,5
|
0,5
|
0,25
|
|
4
|
7
|
8
|
3,5
|
3
|
0,5
|
0,25
|
|
5
|
4
|
5
|
8
|
8
|
0
|
0
|
|
6
|
3
|
4
|
9
|
9
|
0
|
0
|
|
7
|
2
|
2
|
10
|
10
|
0
|
0
|
|
8
|
8
|
9
|
2
|
1
|
1
|
1
|
|
9
|
7
|
8
|
3,5
|
3
|
0,5
|
0,25
|
|
10
|
6
|
6
|
5,5
|
6,5
|
-1
|
1
|
|
0
|
7
|
|||||
Selanjutnya harga bi2 yang telah diperoleh dari
hitungan dalam tabel kolom terakhir dimasukkan dalam rumus korelasi Spearman
Rank :
ρ = 1 – 6.7 : ( 10 x 102 -1 ) =
1 – 0,04 = 0,96
Sebagai interpretasi, angka ini perlu dibandingkan dengan
tabel nilai-nilai ρ(dibaca: rho) dalamTabel 3. Dari tabel itu terlihat
bahwa untuk n = 10, dengan derajat kesalahan 5 % diperoleh harga 0,648 dan
untuk 1 % = 0,794. Hasil ρ hitung ternyata lebih besar
dari ρ tabel
Derajat kesalahan 5 %….. 0,96 > 0,648
Derajat kesalahan 1 %….. 0,96 > 0,794
Hal ini berarti menolak Ho dan menerima Ha.
Kesimpulan :
Terdapat hubungan yang nyata/signifikan antara Motivasi
(Xi) dengan Prestasi (Yi). Dalam hal ini hipotesis nolnya (Ho)
adalah: tidak ada hubungan antara variabel Motivasi (Xi) dengan Prestasi
(Yi). Sedangkan hipotesis alternatifnya (Ha) adalah:terdapat hubungan
yang positif dan signifikan antara variabel Motivasi (Xi) dengan Prestasi
(Yi). Dengan demikian hipotesis nol (Ho) ditolak dan hipotesis alternatif (Ha)
diterima. Atau dengan kata lain bahwa variabel Motivasi mempunyai hubungan yang
signifikan dengan Prestasi.
Tabel 3: Tabel Nilai-nilai ρ (RHO), Korelasi
Spearman Rank
|
N
|
Derajat signifikansi
|
N
|
Derajat signifikansi
|
||
|
5%
|
1%
|
5%
|
1%
|
||
|
5
|
1,000
|
16
|
0,506
|
0,665
|
|
|
6
|
0,886
|
1,000
|
18
|
0,475
|
0,625
|
|
7
|
0,786
|
0,929
|
20
|
0,450
|
0,591
|
|
8
|
0,738
|
0,881
|
22
|
0,428
|
0,562
|
|
9
|
0,683
|
0,833
|
24
|
0,409
|
0,537
|
|
10
|
0,648
|
0,794
|
26
|
0,392
|
0,515
|
|
12
|
0,591
|
0,777
|
28
|
0,377
|
0,496
|
|
14
|
0,544
|
0,715
|
30
|
0,364
|
0,478
|
Sumber:
Moh. Nazir, Ph.D. Metode Penelitian, Penerbit Ghalia
Indonesia, Jakarta, 2003
Sugiono, Prof. Dr. Statistik Nonparametrik Untuk
Penelitian, Penerbit CV ALFABETA Bandung, 2004
Suharto, Bahan Kuliah Statistik, Universitas Muhammadiyah
Metro, 2004
PERTEMUAN KE-8
PENGERTIAN REGRESI LINEAR SEDERHANA DAN REGRESI LINER BERGANDA
REGRESI Secara umum, analisis regresi pada dasarnya
adalah studi mengenai ketergantungan satu variabel dependen (terikat) dengan
satu atau lebih variabel independent (variabel penjelas/bebas), dengan tujuan
untuk mengestimasi dan/atau memprediksi rata-rata populasi atau niiai rata-rata
variabel dependen berdasarkan nilai variabel independen yang diketahui. Pusat
perhatian adalah pada upaya menjelaskan dan mengevalusi hubungan antara suatu
variabel dengan satu atau lebih variabel independen.
Hasil analisis regresi adalah berupa koefisien regresi
untuk masing-masing variable independent. Koefisien ini diperoleh dengan cara
memprediksi nilai variable dependen dengan suatu persamaan. Koefisien regresi
dihitung dengan dua tujuan sekaligus : Pertama, meminimumkan penyimpangan
antara nilai actual dan nilai estimasi variable dependen; Kedua, mengoptimalkan
korelasi antara nilai actual dan nilai estimasi variable dependen berdasarkan
data yang ada. Teknik estimasi variable dependen yang melandasi analisis
regresi disebut Ordinary Least Squares (pangkat kuadrat terkecil biasa).
1. REGRESI LINEAR SEDERHANA
Anda tahu tentang regresi linear sederhana? saya yakin
anda sudah mengetahui hal itu. Sekedar untuk mengingatkan, saya tuliskan
kembali hal-hal yang terkait dengan regresi linear sedrhana ini.
Persamaan di atas adalah rumus dari persamaan regresi
linear sederhana. Y adalah variabel tak bebas, a adalah
koefisien intersep, b adalah kemiringan dan t adalah
variabel bebas. Rumus untuk b adalah :

Dan rumus untuk mendapatkan nilai a adalah
sebagai berikut :

Dalam regresi linear sederhana juga ada yang disebut
dengan koefisien korelasi yang menunjukkan bahwa nilai suatu variabel
bergantung pada perubahan nilai variabel yang lain. Rumus untuk menghitung
koefisien korelasi adalah sebagai berikut :

Referensi :
Makridakis, Spyros dkk. 1993. Metode dan Aplikasi
Peramalan. Erlangga. Jakarta.
2. REGRESI LINEAR BERGANDA
2. REGRESI LINEAR BERGANDA
Analisis regresi linier berganda adalah hubungan secara
linear antara dua atau lebih variabel independen (X1, X2,….Xn) dengan variabel
dependen (Y). Analisis ini untuk mengetahui arah hubungan antara variabel
independen dengan variabel dependen apakah masing-masing variabel independen
berhubungan positif atau negatif dan untuk memprediksi nilai dari variabel
dependen apabila nilai variabel independen mengalami kenaikan atau penurunan.
Data yang digunakan biasanya berskala interval atau rasio.
Persamaan
regresi linear berganda sebagai berikut:
Y’ = a + b1X1+ b2X2+…..+ bnXn
Keterangan:
Y’ = Variabel
dependen (nilai yang diprediksikan)
X1 dan
X2 = Variabel independen
a = Konstanta
(nilai Y’ apabila X1, X2…..Xn = 0)
b = Koefisien
regresi (nilai peningkatan ataupun penurunan)
Contoh kasus:
Kita mengambil contoh kasus pada uji normalitas, yaitu
sebagai berikut: Seorang mahasiswa bernama Bambang melakukan penelitian tentang
faktor-faktor yang mempengaruhi harga saham pada perusahaan di BEJ. Bambang
dalam penelitiannya ingin mengetahui hubungan antara rasio keuangan PER dan ROI
terhadap harga saham. Dengan ini Bambang menganalisis dengan bantuan program
SPSS dengan alat analisis regresi linear berganda. Dari uraian di atas maka
didapat variabel dependen (Y) adalah harga saham, sedangkan variabel independen
(X1 dan X2) adalah PER dan ROI.
Data-data yang di dapat berupa data rasio dan
ditabulasikan sebagai
berikut:
Tabel.
Tabulasi Data (Data Fiktif)
|
Tahun
|
Harga Saham (Rp)
|
PER (%)
|
ROI (%)
|
|
1990
|
8300
|
4.90
|
6.47
|
|
1991
|
7500
|
3.28
|
3.14
|
|
1992
|
8950
|
5.05
|
5.00
|
|
1993
|
8250
|
4.00
|
4.75
|
|
1994
|
9000
|
5.97
|
6.23
|
|
1995
|
8750
|
4.24
|
6.03
|
|
1996
|
10000
|
8.00
|
8.75
|
|
1997
|
8200
|
7.45
|
7.72
|
|
1998
|
8300
|
7.47
|
8.00
|
|
1999
|
10900
|
12.68
|
10.40
|
|
2000
|
12800
|
14.45
|
12.42
|
|
2001
|
9450
|
10.50
|
8.62
|
|
2002
|
13000
|
17.24
|
12.07
|
|
2003
|
8000
|
15.56
|
5.83
|
|
2004
|
6500
|
10.85
|
5.20
|
|
2005
|
9000
|
16.56
|
8.53
|
|
2006
|
7600
|
13.24
|
7.37
|
|
2007
|
10200
|
16.98
|
9.38
|
Langkah-langkah pada program SPSS
Ø Masuk program SPSS
Ø Klik variable view pada SPSS data editor
Ø Pada kolom Name ketik y, kolom Name pada
baris kedua ketik x1, kemudian untuk baris kedua ketik x2.
Ø Pada kolom Label, untuk kolom pada baris
pertama ketik Harga Saham, untuk kolom pada baris kedua ketik PER, kemudian
pada baris ketiga ketik ROI.
Ø Untuk kolom-kolom lainnya boleh dihiraukan
(isian default)
Ø Buka data view pada SPSS data editor, maka
didapat kolom variabel y, x1, dan x2.
Ø Ketikkan data sesuai dengan variabelnya
Ø Klik Analyze - Regression -
Linear
Ø Klik variabel Harga Saham dan masukkan ke
kotak Dependent, kemudian klik variabel PER dan ROI kemudian masukkan ke kotak
Independent.
Ø Klik Statistics, klik Casewise diagnostics,
klik All cases. Klik Continue
Ø Klik OK, maka hasil output yang didapat pada
kolom Coefficients dan Casewise diagnostics adalah sebagai berikut:
Tabel.
Hasil Analisis Regresi Linear Berganda


Persamaan regresinya sebagai berikut:
Y’ = a + b1X1+ b2X2
Y’ = 4662,491 + (-74,482)X1 + 692,107X2
Y’ = 4662,491 - 74,482X1 + 692,107X2
Keterangan:
Y’ = Harga
saham yang diprediksi (Rp)
a =
konstanta
b1,b2 = koefisien regresi
X1 = PER
(%)
X2 = ROI (%)
Persamaan regresi di atas dapat dijelaskan sebagai
berikut:
- Konstanta sebesar 4662,491; artinya jika PER (X1) dan
ROI (X2) nilainya adalah 0, maka harga saham (Y’) nilainya adalah Rp.4662,491.
- Koefisien regresi variabel PER (X1) sebesar
-74,482; artinya jika variabel independen lain nilainya tetap dan PER mengalami
kenaikan 1%, maka harga saham (Y’) akan mengalami penurunan sebesar Rp.74,482.
Koefisien bernilai negatif artinya terjadi hubungan negatif antara PER dengan
harga saham, semakin naik PER maka semakin turun harga saham.
- Koefisien regresi variabel ROI (X2) sebesar
692,107; artinya jika variabel independen lain nilainya tetap dan ROI mengalami
kenaikan 1%, maka harga saham (Y’) akan mengalami peningkatan sebesar
Rp.692,107. Koefisien bernilai positif artinya terjadi hubungan positif antara
ROI dengan harga saham, semakin naik ROI maka semakin meningkat harga saham.
Nilai harga saham yang diprediksi (Y’) dapat dilihat pada
tabel Casewise Diagnostics (kolom Predicted Value). Sedangkan Residual
(unstandardized residual) adalah selisih antara harga saham dengan Predicted
Value, dan Std. Residual (standardized residual) adalah nilai residual yang
telah terstandarisasi (nilai semakin mendekati 0 maka model regresi semakin
baik dalam melakukan prediksi, sebaliknya semakin menjauhi 0 atau lebih dari 1
atau -1 maka semakin tidak baik model regresi dalam melakukan prediksi).
PERTEMUAN KE-9
Pengertian Jaringan Syaraf Tiruan (Neural Network)
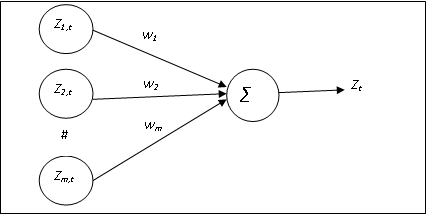
ilustrasi: Struktur jaringan syaraf tiruan
Jaringan syaraf tiruan (JST) atau yang biasa disebut
Artificial Neural Network (ANN) atau Neural Network (NN) saja, merupakan sistem
pemroses informasi yang memiliki karakteristik mirip dengan jaringan syaraf
pada makhluk hidup. Neural network berupa suatu model sederhana dari suatu
syaraf nyata dalam otak manusia seperti suatu unit threshold yang biner.
Neural network merupakan sebuah mesin pembelajaran yang
dibangun dari sejumlah elemen pemrosesan sederhana yang disebut neuron atau
node. Setiap neuron dihubungkan dengan neuron yang lain dengan hubungan
komunikasi langsung melalui pola hubungan yang disebut arsitektur jaringan.
Bobot-bobot pada koneksi mewakili besarnya informasi yang digunakan jaringan.
Metode yang digunakan untuk menentukan bobot koneksi tersebut dinamakan dengan
algoritma pembelajaran. Setiap neuron mempunyai tingkat aktivasi yang merupakan
fungsi dari input yang masuk padanya. Aktivasi yang dikirim suatu neuron ke
neuron lain berupa sinyal dan hanya dapat mengirim sekali dalam satu waktu,
meskipun sinyal tersebut disebarkan pada beberapa neuron yang lain.
Misalkan input Z1,t, Z2,t, …, Zm,t yang bersesuaian
dengan sinyal dan masuk ke dalam saluran penghubung. Setiap sinyal yang masuk
dikalikan dengan bobot koneksinya yaitu w1, w2, …, wm sebelum masuk ke blok
penjumlahan yang berlabel ∑. Kemudian blok penjumlahan akan menjumlahkan semua
input terbobot dan menghasilkan sebuah nilai yaitu Zt_in.
Zt_in = .wi = Zt,1.w1 + Zt,1.w2 + … +
Zm,1.wm
Aktivasi Zt ditentukan oleh fungsi input jaringannya,
Zt=f(Zt_in) dengan f merupakan fungsi aktivasi yang digunakan.
DASAR PEMAHAMAN NEURAL NETWORK
Pendahuluan
Cabang ilmu kecerdasan buatan cukup luas, dan erat
kaitannya dengan disiplin ilmu yang lainnya. Hal ini bisa dilihat dari berbagai
aplikasi yang merupakan hasil kombinasi dari berbagai ilmu. Seperti halnya yang
ada pada peralatan medis yang berbentuk aplikasi. Sudah berkembang bahwa
aplikasi yang dibuat merupakan hasil perpaduan dari ilmu kecerdasan buatan dan
juga ilmu kedokteran atau lebih khusus lagi yaitu ilmu biologi.
Neural Network merupakan kategori ilmu Soft Computing.
Neural Network sebenarnya mengadopsi dari kemampuan otak manusia yang mampu
memberikan stimulasi/rangsangan, melakukan proses, dan memberikan output.
Output diperoleh dari variasi stimulasi dan proses yang terjadi di dalam otak
manusia. Kemampuan manusia dalam memproses informasi merupakan hasil
kompleksitas proses di dalam otak. Misalnya, yang terjadi pada anak-anak,
mereka mampu belajar untuk melakukan pengenalan meskipun mereka tidak
mengetahui algoritma apa yang digunakan. Kekuatan komputasi yang luar biasa
dari otak manusia ini merupakan sebuah keunggulan di dalam kajian ilmu
pengetahuan.
Fungsi dari Neural Network diantaranya adalah:
1.
Pengklasifikasian pola
2.
Memetakan pola yang didapat dari input ke dalam pola baru
pada output
3.
Penyimpan pola yang akan dipanggil kembali
4.
Memetakan pola-pola yang sejenis
5.
Pengoptimasi permasalahan
6.
Prediksi
Sejarah Neural Network
Perkembangan ilmu Neural Network sudah ada sejak tahun
1943 ketika Warren McCulloch dan Walter Pitts memperkenalkan perhitungan model
neural network yang pertama kalinya. Mereka melakukan kombinasi beberapa processing
unit sederhana
bersama-sama yang mampu memberikan peningkatan secara keseluruhan pada kekuatan
komputasi.
 Gambar 2.1
McCulloch & Pitts, penemu pertama Neural Network
Gambar 2.1
McCulloch & Pitts, penemu pertama Neural Network
Hal ini dilanjutkan pada penelitian yang dikerjakan oleh
Rosenblatt pada tahun 1950, dimana dia berhasil menemukan sebuah two-layer
network, yang disebut sebagai perceptron. Perceptron
memungkinkan untuk pekerjaan klasifikasi pembelajaran tertentu dengan
penambahan bobot pada setiap koneksi antar-network.
 Gambar 2.2
Perceptron
Gambar 2.2
Perceptron
Keberhasilan perceptron dalam pengklasifikasian pola
tertentu ini tidak sepenuhnya sempurna, masih ditemukan juga beberapa
keterbatasan didalamnya. Perceptron tidak mampu untuk menyelesaikan
permasalahan XOR (exclusive-OR).
Penilaian terhadap keterbatasan neural network ini membuat penelitian di bidang
ini sempat mati selama kurang lebih 15 tahun. Namun demikian, perceptron
berhasil menjadi sebuah dasar untuk penelitian-penelitian selanjutnya di bidang
neural network. Pengkajian terhadap neural network mulai berkembang lagi
selanjutnya di awal tahun 1980-an. Para peneliti banyak menemukan bidang
interest baru pada domain ilmu neural network. Penelitian terakhir diantaranya
adalah mesin Boltzmann, jaringan Hopfield, model pembelajaran kompetitif, multilayer
network, dan teori model resonansi adaptif.
Untuk saat ini, Neural Network sudah dapat diterapkan pada
beberapa task, diantaranya classification, recognition, approximation,
prediction, clusterization, memory simulation dan banyak task-task berbeda yang
lainnya, dimana jumlahnya semakin bertambah seiring berjalannya waktu.
Konsep Neural Network
1. Proses Kerja Jaringan Syaraf Pada Otak Manusia
Ide dasar Neural Network dimulai dari otak manusia,
dimana otak memuat sekitar 1011 neuron. Neuron ini berfungsi memproses
setiap informasi yang masuk. Satu neuron memiliki 1 akson, dan minimal 1
dendrit. Setiap sel syaraf terhubung dengan syaraf lain, jumlahnya mencapai
sekitar 104 sinapsis.
Masing-masing sel itu saling berinteraksi satu sama lain yang menghasilkan
kemampuan tertentu pada kerja otak manusia.
 Gambar 2.3
Struktur Neuron pada otak manusia
Gambar 2.3
Struktur Neuron pada otak manusia
Dari gambar di atas, bisa dilihat ada beberapa bagian dari otak manusia,
yaitu:
1.
Dendrit (Dendrites)
berfungsi untuk mengirimkan impuls yang diterima ke badan sel syaraf.
2.
Akson (Axon)
berfungsi untuk mengirimkan impuls dari badan sel ke jaringan lain
3.
Sinapsis berfungsi sebagai unit fungsional di antara dua
sel syaraf.
Proses yang terjadi pada otak manusia adalah:
Sebuah neuron menerima impuls dari neuron lain melalui
dendrit dan mengirimkan sinyal yang dihasilkan oleh badan sel melalui akson.
Akson dari sel syaraf ini bercabang-cabang dan berhubungan dengan dendrit dari
sel syaraf lain dengan cara mengirimkan impuls melalui sinapsis. Sinapsis
adalah unit fungsional antara 2 buah sel syaraf, misal A dan B, dimana yang
satu adalah serabut akson dari neuron A dan satunya lagi adalah dendrit dari
neuron B. Kekuatan sinapsis bisa menurun/meningkat tergantung seberapa besar
tingkat propagasi (penyiaran) sinyal yang diterimanya. Impuls-impuls sinyal
(informasi) akan diterima oleh neuron lain jika memenuhi batasan tertentu, yang
sering disebut dengan nilai ambang (threshold).
2. Struktur Neural Network
Dari struktur neuron pada otak manusia, dan proses kerja
yang dijelaskan di atas, maka konsep dasar pembangunan neural network buatan (Artificial Neural Network)
terbentuk. Ide mendasar dari Artificial Neural Network (ANN) adalah mengadopsi
mekanisme berpikir sebuah sistem atau aplikasi yang menyerupai otak manusia,
baik untuk pemrosesan berbagai sinyal elemen yang diterima, toleransi terhadap
kesalahan/error, dan juga parallel
processing.
 Gambar 2.4
Struktur ANN
Gambar 2.4
Struktur ANN
Karakteristik dari ANN dilihat dari pola hubungan antar
neuron, metode penentuan bobot dari tiap koneksi, dan fungsi aktivasinya.
Gambar di atas menjelaskan struktur ANN secara mendasar, yang dalam
kenyataannya tidak hanya sederhana seperti itu.
1.
Input, berfungsi seperti dendrite
2.
Output, berfungsi seperti akson
3.
Fungsi aktivasi, berfungsi seperti sinapsis
Neural network dibangun dari banyak node/unit yang
dihubungkan oleh link secara langsung. Link dari unit yang satu ke unit yang
lainnya digunakan untuk melakukan propagasi aktivasi dari unit pertama ke unit
selanjutnya. Setiap link memiliki bobot numerik. Bobot ini menentukan kekuatan
serta penanda dari sebuah konektivitas.
Proses pada ANN dimulai dari input yang diterima oleh
neuron beserta dengan nilai bobot dari tiap-tiap input yang ada. Setelah masuk
ke dalam neuron, nilai input yang ada akan dijumlahkan oleh suatu fungsi
perambatan (summing function),
yang bisa dilihat seperti pada di gambar dengan lambang sigma (∑). Hasil
penjumlahan akan diproses oleh fungsi aktivasi setiap neuron, disini akan
dibandingkan hasil penjumlahan dengan threshold (nilai ambang) tertentu. Jika nilai
melebihi threshold, maka aktivasi neuron
akan dibatalkan, sebaliknya, jika masih dibawah nilai threshold,
neuron akan diaktifkan. Setelah aktif, neuron akan mengirimkan nilai output
melalui bobot-bobot outputnya ke semua neuron yang berhubungan dengannya.
Proses ini akan terus berulang pada input-input selanjutnya.
ANN terdiri dari banyak neuron di dalamnya. Neuron-neuron
ini akan dikelompokkan ke dalam beberapa layer. Neuron yang terdapat pada tiap
layer dihubungkan dengan neuron pada layer lainnya. Hal ini tentunya tidak
berlaku pada layer input dan output, tapi hanya layer yang berada di antaranya.
Informasi yang diterima di layer input dilanjutkan ke layer-layer dalam ANN
secara satu persatu hingga mencapai layer terakhir/layer output. Layer yang
terletak di antara input dan output disebut sebagai hidden
layer. Namun, tidak semua ANN memiliki hidden layer, ada juga yang
hanya terdapat layer input dan output saja.
PERTEMUAN KE-10
Keandalan (Reliability)
Keandalan
adalah suatu penerapan perancangan pada komponen sehingga komponen dapat
melaksanakan fungsinya dengan baik, tanpa kegagalan, sesuai rancangan atau
proses yang dibuat. Keandalan merupakan probabilitas bahwa suatu sistem
mempunyai performansi sesuai dengan fungsi yang diharapkan dalam selang waktu
dan kondisi operasi tertentu. Secara umum keandalan merupakan ukuran kemampuan
suatu komponen beroperasi secara terus menerus tanpa adanya kerusakan, tindakan
perawatan pencegahan yang dilakukan dapat meningkatkan keandalan sistem.
Fokus
utama dari perancangan sistem keandalan adalah karakteristik kekuatan tekanan
komponen. Bagian-bagian komponen dirancang dan dihasilkan untuk bekerja dengan
cara yang spesifik ketika beroperasi dibawah kondisi normal. Jika kekuatan
ditambahkan akan memaksakan beban elektrik, karena berhubungan dengan variasi,
getaran, goncangan, kelembaban dan semacamnya, kemudian kegagalan yang tak
terduga akan terjadi dan sistem keandalan menjadi kurang diantisipasi. Selain
itu juga, jika komponen digunakan melewati batas normal maka kelelahan akan
terjadi, komponen yang gagal akan menjadi lebih banyak dari yang diharapkan.
Bagaimanapun juga kondisi-kondisi tekanan akan mengakibatkan penurunan
keandalan, menyebabkan peningkatan kebutuhan pememliharaan dan dibawah kondisi
tekanan akan menimbulkan biaya yang mahal sebagai hasil atas kelebihan
perancangan.
Analisis
kekuatan tekanan sering digunakan untuk mengevaluasi probabilitas dari
pengidentifikasikan situasi dimana nilai dari tekanan terlalu besar atau
kekuatan lebih kecil dari pada nilai normal. Seperti analisis pemenuhan yang
ditunjukkan oleh langkah-langkah berikut:
1. Untuk menyeleksi
komponen, menentukan nominal penekanan seperti fungsi beban temperatur/ suhu,
getaran, guncangan, perlengkapan fisik, waktu dan lainnya.
2. Mengidentifikasi
faktor-faktor yang mempengaruhi tingkat tekanan maksimum, seperti faktor
penekanan konsentrasi, faktor beban statis dan dinamis, penekanan terhadap
hasil pabrikasi dan perlakuan panas, faktor penekanan lingkungan dan lainnya.
3. Mengidentifikasi
penekanan komponen kritis dan mengkalkulasi arti setiap penekanan kritis yang
dapat direnggangkan secara maksimal dan menghilangkan penekanannya.
4. Menentukan
distribusi penekanan kritis untuk masa penggunaan komponen yang sudah
ditetapkan. Menganalisa parameter distribusi dan mengidentifikasi batas
keamanan. Mengaplikasikan distribusi dengan asumsi distribusi normal, poisson,
gamma, log normal dan lainnya.
5. Untuk setiap
komponen kritis perancangan batas keamanan tidak cukup, tindakan korektif juga
harus dilakukan, ini akan sesuai dengan isi setiap komponen bagian pengganti,
beberapa pemborosan yang harus bertambah atau melengkapi perancangan
unsur sistem yang menjadi masalah.
Model
komputerisasi keandalan dapat digunakan untuk memfasilitasi pemenuhan analisis
kekuatan tekanan. Perbedaan faktor keandalan atau batasan faktor dengan
distribusi yang lebih spesifik dapat diterapkan pada beberapa elemen diagram
blok keandalan. Penyebab dan dampaknya dievaluasi dan rata-rata kerusakan
masing-masing komponen dapat disesuaikan untuk mencerminkan efek dari tekanan
komponen yang terlibat.
Model
keandalan dengan perbaikan sempurna digunakan untuk alokasi kebutuhan awal,
konduktansi dari analisis tekanan, prediksi keandalan dan penilaian terakhir
untuk memberikan konfigurasi sistem. Hasil dari beberapa aktivitas menyediakan
kunci masuk yang diperlukan untuk sebuah perancangan pemeliharaan. Hasil dari
alokasi keandalan digunakan dalam pemenuhan alokasi pemeliharaan penekanan.
Analisis kekuatan dapat membantu beberapa titik keburukan atau ancaman dalam
sistem, dimana penekanan yang lebih besar membutuhkan terminologi dari
pemeliharaan dan dukungan.
Mengukur Reliability?
Sekali lagi ‘reliability’ adalah indikator apakah sebuah
pertanyaan jika ditanyakan berulang-ulang kali baik kepada orang yang sama
maupun kepada orang lain jawabannya akan cenderung sama (konsisten/berulang).
Dengan pengertian ini maka ada beberapa cara untuk
mengukur reliability:
1. Test-Retest Reliability
 Ini cara paling
sederhana menguji reliability sesuai dengan definisinya di atas, yakni dengan
cara mencoba questionnaire yang sama kepada respondents yang
sama lebih dari satu kali (misal 2x) dalam waktu yang
berbeda (jeda waktu tertentu). Jadi nilai reliability-nya ditentukan
nilai Korelasi item-item yang sama untuk periode survey yang
berbeda.
Ini cara paling
sederhana menguji reliability sesuai dengan definisinya di atas, yakni dengan
cara mencoba questionnaire yang sama kepada respondents yang
sama lebih dari satu kali (misal 2x) dalam waktu yang
berbeda (jeda waktu tertentu). Jadi nilai reliability-nya ditentukan
nilai Korelasi item-item yang sama untuk periode survey yang
berbeda.Kelemahannya: pada survey ke-2 orang cenderung mencoba mengingat jawabannya sebelumnya bukan focus pada pertanyaannya. Atau untuk kasus pertanyaan yang mengukur mood perasaan, jawaban bisa berubah (meskipun ada orang yang memiliki kepribadian mantap, suasana hati selalu tenang)
2. Inter-Rater Reliability
 Cara mudah yang
kedua yakni dengan memberikan pertanyaan yang sama kepada lebih dari satu
respondents kemudian membandingkan jawaban antar respondent. Jadi nilai
reliability-nya dihitung dari nilai Korelasi item yang
sama untuk respondents yang berbeda.
Cara mudah yang
kedua yakni dengan memberikan pertanyaan yang sama kepada lebih dari satu
respondents kemudian membandingkan jawaban antar respondent. Jadi nilai
reliability-nya dihitung dari nilai Korelasi item yang
sama untuk respondents yang berbeda.Namun metode ini TIDAK DIREKOMENDASIkan karena tentu kita tidak bisa berasumsi bahwa masing-masing respondents menjawab dengan serius atau dalam kondisi yang sama.
3. INTERNAL CONSISTENCY
Intinya metode ini dipakai jika kita hanya memiliki
kesempatan mencoba questionnaires kita 1x pada sekelompok respondents. Jadi
disini, reliability item2 pertanyaan yang menanyakan faktor atau construct
yang sama akan dihitung berdasarkan nilai korelasinya (mestinya item2 yang
menanyakan construct yang sama memiliki jawaban yang hampir sama..atau memiliki
korelasi yang tinggi). Jadi disini Reliability dihitung berdasar konsistensi
internal jawaban tiap item yang menanyakan construct yang sama.
Terdapat 4 pilihan metode pengukuran Reliability
berdasarkan Internal Consistency:
a. Cronbach’s Alpha
a. Cronbach’s Alpha
b. Average Inter-item Correlation
c. Average Itemtotal Correlation
d. Split-Half Reliability
*** **>>> Apa yang saya pilih???
karena saya make’ SPSS dan saya pengin yang PALING MUDAH, maka saya milih:
karena saya make’ SPSS dan saya pengin yang PALING MUDAH, maka saya milih:
1. Cronbach’s Alpha
nilai Alpha ini menunjukkan nilai rata-rata (average) korelasi antar item yang mengukur construct yang sama.
Nilai Alpha: 0 – 1 (semakin besar semakin reliable), tetapi Nunnaly (1978 in Pallant 2005:6 …lengkapnya ‘Julie Pallant, 2005, SPSS Survival Manual, Ligare, Sidney) merekomendasikan nilai Alpha minimum 0.7
nilai Alpha ini menunjukkan nilai rata-rata (average) korelasi antar item yang mengukur construct yang sama.
Nilai Alpha: 0 – 1 (semakin besar semakin reliable), tetapi Nunnaly (1978 in Pallant 2005:6 …lengkapnya ‘Julie Pallant, 2005, SPSS Survival Manual, Ligare, Sidney) merekomendasikan nilai Alpha minimum 0.7
Namun Pallant (2005:6) menyatakan bahwa nilai Cronbach’s
Alpha ini juga dipengaruhi oleh banyaknya item pertanyaan, jika item pertanyaan
sedikit (kurang dari 10 pertanyaan untuk construct yang sama) nilai Alpha akan
kecil. Olehkarena itu untuk item pertanyaan yang kurang dari 10, Pallant
menyarankan menghitung Internal Consistency dengan metode Average
Inter-item Correlation!
Nilai optimum Mean Inter-item Correlation: 0.2 –
o.4 (Brick & Cheek, 1986 in Pattal 2005:6)
2. Average Inter-item Correlation
 Intinya metode ini
menghitung perbandingan (korelasi) jawaban antar item (dibuat matriks),
selanjutnya dihitung rata-rata korelasinya.
Intinya metode ini
menghitung perbandingan (korelasi) jawaban antar item (dibuat matriks),
selanjutnya dihitung rata-rata korelasinya.
Teknisnya pake SPSS???:
Kalo data udah di-kode kan dan di input ke ‘Data View’
SPSS, selanjutnya
menu “Analyze” > ‘Scale‘ > ‘Reliability Analysis‘ :
Pilih ‘Model: Alpha‘ dan masukkan dikolom kanan
item2 pertanyaan yang mengukur construct yang sama
klik tombol ‘Statistics’: aktifkan
dibagian ‘Descriptive for’ aktifin aja semua
dibagian ‘Inter-Item’ aktifkan ‘Correlations‘
dibagian ‘Summaries’ aktifkan ‘Means’ ama ‘Correlations‘ (ini buat ngitung means korelasinya nanti)
dah continue OK
dibagian ‘Descriptive for’ aktifin aja semua
dibagian ‘Inter-Item’ aktifkan ‘Correlations‘
dibagian ‘Summaries’ aktifkan ‘Means’ ama ‘Correlations‘ (ini buat ngitung means korelasinya nanti)
dah continue OK
dibagian Output SPSS lihat:
jika mau make nilai Cronbach’s Alpha –>
lihat di tabel “reliability Statistics”
jika mau make nilai Mean Inter-Item Corelations –> lihat di tabel “Summary Item Statistics“
jika mau make nilai Mean Inter-Item Corelations –> lihat di tabel “Summary Item Statistics“
PERTEMUAN KE-11
statistik non parametrik
Pengertian statistik non parametrik adalah test yang modelnya tidak
menetapakan syarat-syaratnya yang mengenai parameter-parameter populasi yang merupakan
induk sampel penelitiannya. Oleh karena itu observasi-observasi
independent dan variabel yang diteliti pada dasarnya memiliki kontinuitas. Uji
metode non parametrik atau bebas sebaran adalah prosedur pengujian hipotesa
yang tidak mengasumsikan pengetahuan apapun mengenai sebaran populasi yang
mendasarinya kecuali selama itu kontinu.
Dalam kegiatan peneliatian, biasanya lebih banyak digunakan analisis
statistic parametrik daripada statistik non parametrik. Statistik parametrik
digunakan jika kita telah mengetahui model matematis dari distribusi populasi
suatu data yang akan dianalisis. Jika kita tidak mengetahui suatu model
distribusi populasi dari suatu data dan jumlah data relatif kecil atau asumsi
kenormalan tidak selalu dapat dijamin penuh,maka kita harus menggunakan
statistik non parametrik (statistik bebas distribusi).
Statistik non parametrik memiliki keunggulan atau kelebihan yaitu
kebanyakan prosuder non parametrik memerlukan asumsi dalam jumlah yang minimal
maka kemungkinan untuk untuk beberapa prosedur non parametrik
perhitunganperhitungan dapat dilakukan dengan cepat dan mudah, terutama bila
terpaksa dilakukan secara manual. Jadi pengguna prosedur-prosedur ini menghemat
waktu yang diperlukan untuk perhitungan dan ini merupakan bahan pertimbangan
bila hasil penyajian harus segera tersaji atau bila mesin hitung berkemampuan
tinggi tidak tersedia. Dengan statistik non parametrik para peneliti juga
dengan dasar matematik dan statistik yang kurang biasanya konsep dan metode
prosedur non parametric mudah dipahami. Prosedur-prosedur non parametrik boleh
menggunakan skala pengukuran.
Sedangkan kelemahan dari statistik non parametrik adalah karena
perhitunganperhitungan yang dibutuhkan untuk kebanyakan prosedur non parametrik
cepat dan sederhana, prosedur ini kadang-kadang digunakan untuk kasus-kasus
yang lebih tepat bilah ditangani prosedur-prosedur non paramaetrik sehingga
cara seperti ini sering menyebabkan pemborosan informasi. Kendatipun prosedur
non parametrik terkenal karena prinsip perhitungan yang sederhana, pekerjaan
hitung-menghitung selalu membutuhkan banyak tenaga dan menimbulkan kejenuhan.
Dalam
implementasi, penggunaan prosedur yang tepat merupakam tujuan dari peneliti.
Beberapa parameter yang dapat digunakan sebagai dasar dalam penggunaan
statistik non parametrik adalah:
- Hipotesa yang diuji tidak
melibatkan parameter populasi.
- Skala yang digunakan lebih lemah
dari skala prosedur parametrik.
- Asumsi-asumsi parametrik tidak
terpenuhi.
Banyak
prosedur non parametrik yang dapat digunakan dalam analisis
statistik,diantaranya:
- Uji Chi-Kuadrat
- Uji Binomial
- Uji Run
- Uji Kolmogrov Smirnov Satu
Sampel
- Uji Dua Sampel Independen
- Uji beberapa sampel
independen
- Uji dua sampel yang
berkaitan
- Uji beberapa sampel yang
berkaitan
STATISTIK
NON-PARAMETRIK
Statistik Non-Parametrik merupakan alternatif dari
statistik parametrik ketika asumsi-asumsi yang mendasari dalam statistik
parametrik tidak dapat terpenuhi. Untuk mengenal lebih jauh mengenai statistik
non-parametrik. Sebelum berbicara mengenai statistik nonparametrik, ada baiknya
kita bahas apa itu statistik parametrik.
Pada umumnya, setelah data dikumpulkan, langkah
selanjutnya adalah mencari nilai tengahnya (mean)
dan simpangannya (variance),
kemudian dilakukan uji-z atau uji-t. Semua tindakan yang dilakukan di
atas merupakan prosedur umum statistik parametric yang mengacu pada suatu
parameter yang dipunyai oleh sebuah distribusi.
Berbeda dengan statistik parametrik, statistik
nonparametrik adalah prosedur statistik yang tidak mengacu pada parameter
tertentu. Itulah sebabnya, statistik nonparametrik sering disebut sebagai
prosedur yang bebas distribusi (free-distibution
procedures).
Banyak orang berpendapat, jika data yang dikumpulkan
terlalu kecil maka prosedur statistik nonparametrik lebih baik digunakan.
Pendapat ini bisa benar dan bisa pula salah. Masalahnya adalah, bagaimana
mendefinisikan besar-kecilnya suatu data? Bukankah hal ini sangat relatif? Yang
jelas, kita pasti menggunakan statistik nonparametrik bila kita tidak
mengetahui dengan pasti distribusi dari data yang kita amati.
Namun jika kita yakin data yang diamati berdistribusi
normal, misalkan dibuktikan dengan memakai uji statistik, maka kita bisa
memakai prosedur statistik parametrik untuk distribusi normal. Sebaliknya,
walaupun data yang dikumpukan berjumlah besar, tetapi tidak dapat dipastikan
distribusinya, maka sebaiknya dipakai prosedur statistik nonparametrik.
Statistik nonparametrik mempunyai beberapa kelebihan dan
kekurangan. Kelebihannya antara lain adalah:
1. Tingkat kesalahan penggunaan prosedur statistik nonparametrik relatif kecil
karena statistik jenis ini tidak memerlukan banyak asumsi.
2. Perhitungan yang harus dilakukan pada umumnya sederhana dan mudah,
khususnya untuk data yang kecil.
3. Konsep dalam statistik nonparametrik mudah untuk dimengerti.
4. Dapat digunakan untuk menganalisa data yang berbentuk hitungan maupun
peringkat (rank).
Sebaliknya, kekurangan statistik nonparametrik yang
paling utama adalah hasil tidak selalu sesuai dengan yang diharapkan karena
kesederhanaan perhitungannya. Namun, walaupun perhitungan dalam statistik
nonparametrik sangat sederhana, bila jumlah datanya sangat besar maka
dibutuhkan perhitungan yang sangat lama. Untuk kasus yang demikian, prosedur
statistik parametrik lebih tepat untuk digunakan.
Berikut adalah beberapa uji statistik yang biasa dipakai.
Kolom pertama menguraikan uji statistik parametrik, sementara kolom kedua
menampilkan uji statistik nonparametrik yang sepadan.
|
Uji Parametrik (menggunakan asumsi
distribusi Normal)
|
Uji nonparametrik yang bersesuaian
|
Tujuan
|
|
Uji – t untuk
sample bebas
|
Uji Mann-Whitney U; Uji Wilcoxon
jumlah peringkat
|
Membandingkan dua sample bebas
|
|
Uji – t berpasangan
|
Uji Wilcoxon pasangan dengan peringkat
yang cocok
|
Meneliti perbedaan dalam suatu
grup
|
|
Koefisien korelasi Pearson
|
Koefisien korelasi peringkat Spearman
|
Mengetahui hubungan korelasi linier
antara dua peubah
|
|
Analisa varians satu arah (Uji F )
|
Analisa varians dengan menggunakan
peringkat Kruskal-Wallis
|
Membandingkan tiga grup atau lebih
|
|
Analisa varians dua arah
|
Analisa varians dua arah Friedman
|
Mabandingkan tiga grup atau lebih
dengan menggunakan dua faktor yang berbeda
|
Jadi dapat disumpulkan bahwa penggunaan statistik
nonparametrik lebih diutamakan jika hipotetis yang akan diuji tidak melibatkan
parameter dari populasi. Data yang diambil tidak memenuhi syarat yang
ditetapkan oleh statistik parametrik dan asumsi-asumsinya ditolak, atau bila
kita membutuhkan hasil yang cepat sebelum melakukan penelitian berikutnya.
Ada terdapat enam persyaratan yang harus dipenuhi pada
uji asumsi klasik agar data observasi tersebut dapat menggunakan uji statistik
parametrik atau statistik inferesial, yaitu :
1. Uji kerandoman
2. Uji normalitas
3. Uji linearitas
4. Uji heteroskedastisitas
5. Uji Multikolinearitas
6. Uji Autokorelasi
Mari kita sama-sama membahasnya satu persatu dari keenam
persyaratan uji asumsi klasik tersebut di atas.
1. Uji kerandoman
Kerandoman data diperlukan karena data observasi yang homogen akan mengakibatkan bentuk distribusi tidak normal, disamping itu kerandoman data mencerminkan atau representatif terhadap populasinya, karena data yang diambil atau dicuplik dari suatu populasi seharusnya data itu mencerminkan sifat-sifat dari populasinya.Hal ini juga menyangkut variabel random, di mana variabel random adalah variabel yang nilainya merupakan hasil dari suatu peristiwa, sehingga data tersebut tidak bias atau tidak gayut atau nilai-nilai yang dihasilkan tidak berpola (heterogen).
Kerandoman data diperlukan karena data observasi yang homogen akan mengakibatkan bentuk distribusi tidak normal, disamping itu kerandoman data mencerminkan atau representatif terhadap populasinya, karena data yang diambil atau dicuplik dari suatu populasi seharusnya data itu mencerminkan sifat-sifat dari populasinya.Hal ini juga menyangkut variabel random, di mana variabel random adalah variabel yang nilainya merupakan hasil dari suatu peristiwa, sehingga data tersebut tidak bias atau tidak gayut atau nilai-nilai yang dihasilkan tidak berpola (heterogen).
2. Uji
normalitas
Uji normalitas bertujuan untuk menguji apakah dalam model regresi, variabel terikat dan variabel bebas keduanya mempunyai distribusi normal ataukah tidak. Model regresi yang baik adalah memiliki distribusi data normal atau mendekati normal.Ada beberapa pendekatan yang dapat dilakukan untuk mengetahui apakah data tersebut berdistribusi normal atau tidak yaitu : analisis grafik dan analisis statistik. Analisis statistik bisa digunakan uji Kolmogorov Smirnov, atau dengan memanfaatkan deskripsi data nilai-nilai skewness dan kurtosisnya.
Uji normalitas bertujuan untuk menguji apakah dalam model regresi, variabel terikat dan variabel bebas keduanya mempunyai distribusi normal ataukah tidak. Model regresi yang baik adalah memiliki distribusi data normal atau mendekati normal.Ada beberapa pendekatan yang dapat dilakukan untuk mengetahui apakah data tersebut berdistribusi normal atau tidak yaitu : analisis grafik dan analisis statistik. Analisis statistik bisa digunakan uji Kolmogorov Smirnov, atau dengan memanfaatkan deskripsi data nilai-nilai skewness dan kurtosisnya.
3. Uji
linearitas
Uji ini biasanya dilakukan untuk melihat apakah spesifikasi model yang digunakan sudah benar atau tidak. Apakah fungsi yang digunakan dalam suatu studi empiris sebaiknya berbentuk linear, kuadrat atau kubik. Dengan uji ini akan diperoleh informasi apakah model empiris sebaiknya linear, kuadrat atau kubik.Ada beberapa pendekatan yang dapat dilakukan untuk mengetahui apakah model persamaan regresi tersebut linear atau tidak yaitu : uji Durbin-Watson, uji Ramsey test dan uji Lagrange Multiplier.
Uji ini biasanya dilakukan untuk melihat apakah spesifikasi model yang digunakan sudah benar atau tidak. Apakah fungsi yang digunakan dalam suatu studi empiris sebaiknya berbentuk linear, kuadrat atau kubik. Dengan uji ini akan diperoleh informasi apakah model empiris sebaiknya linear, kuadrat atau kubik.Ada beberapa pendekatan yang dapat dilakukan untuk mengetahui apakah model persamaan regresi tersebut linear atau tidak yaitu : uji Durbin-Watson, uji Ramsey test dan uji Lagrange Multiplier.
4. Uji
heteroskedastisitas
Uji heteroskedastisitas bertujuan menguji apakah dalam model regresi terjadi ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain. Jika variance dari residual satu pengamatan ke pengamatan yang lain tetap maka disebut Homoskedastisitas dan sebaliknya. Model regresi yang baik adalah yang homoskedastisitas. Sebagai tambahan bahwa pada umumnya data yang diambil dari populasi secara berturut-turut atau time series pada umumnya cenderung terjadi homoskedastisitas, sedangkan data yang cross-section kemungkinan besar tidak terjadi homoskedastisitas.Ada beberapa pendekatan untuk mengetahui apakah dalam model regresi terdapat kesamaan variance atau tidak yaitu : Pendekatan grafik yang dihasilkan dengan memplot antara nilai prediksi variabel terikat (ZPRED) dengan residualnya (SRESID). Deteksi ada tidaknya heteroskedastisitas dapat dilakukan dengan melihat ada tidaknya pola tertentu pada grafik scatterplot antara SRESID dan ZPRED. Dimana sumbu Y adalah Y yang telah diprediksi dan sumbu X adalah residual (Y prediksi – Y sesungguhnya) yang telah distudentized.Dasar analisisnya adalah jika pola tertentu, seperti titik-titik yang ada membentuk pola tertentu yang teratur (bergelombang, melebar kemudian menyempit) maka mengindikasikan telah terjadi heteroskedastisitas. Dan jika tidak ada pola yang jelas, serta titik-titik menyebar di atas dan di bawah angka 0 pada sumbu Y, maka telah terjadi homoskedastisitas. Pendekatan statistik dengan menggunakan uji White, uji Glejser dan uji Park.
Uji heteroskedastisitas bertujuan menguji apakah dalam model regresi terjadi ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain. Jika variance dari residual satu pengamatan ke pengamatan yang lain tetap maka disebut Homoskedastisitas dan sebaliknya. Model regresi yang baik adalah yang homoskedastisitas. Sebagai tambahan bahwa pada umumnya data yang diambil dari populasi secara berturut-turut atau time series pada umumnya cenderung terjadi homoskedastisitas, sedangkan data yang cross-section kemungkinan besar tidak terjadi homoskedastisitas.Ada beberapa pendekatan untuk mengetahui apakah dalam model regresi terdapat kesamaan variance atau tidak yaitu : Pendekatan grafik yang dihasilkan dengan memplot antara nilai prediksi variabel terikat (ZPRED) dengan residualnya (SRESID). Deteksi ada tidaknya heteroskedastisitas dapat dilakukan dengan melihat ada tidaknya pola tertentu pada grafik scatterplot antara SRESID dan ZPRED. Dimana sumbu Y adalah Y yang telah diprediksi dan sumbu X adalah residual (Y prediksi – Y sesungguhnya) yang telah distudentized.Dasar analisisnya adalah jika pola tertentu, seperti titik-titik yang ada membentuk pola tertentu yang teratur (bergelombang, melebar kemudian menyempit) maka mengindikasikan telah terjadi heteroskedastisitas. Dan jika tidak ada pola yang jelas, serta titik-titik menyebar di atas dan di bawah angka 0 pada sumbu Y, maka telah terjadi homoskedastisitas. Pendekatan statistik dengan menggunakan uji White, uji Glejser dan uji Park.
5. Uji
multikolinearitas
Uji multikolinearitas bertujuan untuk menguji apakah model regresi ditemukan adanya korelasi antar variabel bebas. Model regresi yang baik seharusnya tidak terjadi korelasi antara variabel bebas (tidak terjadi multikolinearitas). Jika variabel bebas saling berkorelasi, maka variabel-variabel ini tidak ortogonal. Variabel ortogonal adalah variabel bebas yang nilai korelasi antar sesama variabel bebas sama dengan nol.Untuk mendeteksi ada atau tidaknya multikolinearitas di dalam model regresi adalah sebagai berikut :Nilai R ² yang dihasilkan oleh suatu estimasi model regresi empiris sangat tinggi, tetapi secara individual variabel-variabel bebas banyak yang tidak signifikan mempengaruhi variabel terikat. Menganalisis matrik korelasi variabel-variabel bebas.
Uji multikolinearitas bertujuan untuk menguji apakah model regresi ditemukan adanya korelasi antar variabel bebas. Model regresi yang baik seharusnya tidak terjadi korelasi antara variabel bebas (tidak terjadi multikolinearitas). Jika variabel bebas saling berkorelasi, maka variabel-variabel ini tidak ortogonal. Variabel ortogonal adalah variabel bebas yang nilai korelasi antar sesama variabel bebas sama dengan nol.Untuk mendeteksi ada atau tidaknya multikolinearitas di dalam model regresi adalah sebagai berikut :Nilai R ² yang dihasilkan oleh suatu estimasi model regresi empiris sangat tinggi, tetapi secara individual variabel-variabel bebas banyak yang tidak signifikan mempengaruhi variabel terikat. Menganalisis matrik korelasi variabel-variabel bebas.
Jika
antar variabel bebas ada korelasi yang cukup tinggi (umumnya diatas 0,90), maka
hasil ini merupakan indikasi adanya multikolinearitas. Tidak adanya korelasi
yang tinggi antar variabel bebas tidak berarti bebas dari multikolinearitas.
Multikolinearitas
dapat disebabkan karena adanya efek kombinasi dua atau lebih variabel
bebas.Multikolinearitas dapat juga dilihat dari : nilai tolerance dan lawannya
variance inflation faktor (VIF). Kedua ukuran ini menunjukkan setiap variabel
bebas manakah yang dijelaskan oleh variabel bebas lainnya. Dalam pengertian
sederhana setiap variabel bebas menjadi variabel terikat dan diregres terhadap
variabel bebas lainnya. Tolerance mengukur variabilitas variabel bebas yang
terpilih yang tidak dapat dijelaskan oleh variabel bebas lainnya.
Jadi
nilai tolerance yang rendah sama dengan nilai VIF tinggi adalah menunjukkan
adanya kolinearitas yang tinggi. Nilai cut-off yang umum dipakai adalah nilai
tolerance 0,10 atau sama dengan nilai VIF di atas 10%.
6. Uji
autokorelasi
Uji autokorelasi bertujuan menguji apakah dalam suatu model regresi linear ada korelasi antara residual (kesalahan pengganggu) pada periode sebelum dan sesudah, jika terjadi korelasi maka dinamakan terjadi autokorelasi, dan model regresi yang baik adalah yang tidak mengandung autokorelasi. Pada data silang waktu (cross-section) masalah autokorelasi jarang ditemui, namun pada data runtun waktu (time-series) masalah autokorelasi sering ditemui.Ada beberapa pendekatan yang digunakan untuk mengetahui apakah model regresi terdapat autokorelasi atau tidak yaitu : uji Durbin-Watson digunakan untuk autokorelasi tingkat satu (firs order autocorrelation) dan mensyaratkan adanya intercept (konstanta) dalam model regresi dan tidak ada variabel lag di antara variabel bebas. Uji lainnya seperti uji Lagrange Multiplier (LM Test) dan uji Statistik Q : Box – Pierce dan Ljung Box.Untuk kedua uji yang terakhir ini mensyaratkan bahwa data observasi di atas 100 sampel dan derajat autokorelasi lebih dari satu.
Uji autokorelasi bertujuan menguji apakah dalam suatu model regresi linear ada korelasi antara residual (kesalahan pengganggu) pada periode sebelum dan sesudah, jika terjadi korelasi maka dinamakan terjadi autokorelasi, dan model regresi yang baik adalah yang tidak mengandung autokorelasi. Pada data silang waktu (cross-section) masalah autokorelasi jarang ditemui, namun pada data runtun waktu (time-series) masalah autokorelasi sering ditemui.Ada beberapa pendekatan yang digunakan untuk mengetahui apakah model regresi terdapat autokorelasi atau tidak yaitu : uji Durbin-Watson digunakan untuk autokorelasi tingkat satu (firs order autocorrelation) dan mensyaratkan adanya intercept (konstanta) dalam model regresi dan tidak ada variabel lag di antara variabel bebas. Uji lainnya seperti uji Lagrange Multiplier (LM Test) dan uji Statistik Q : Box – Pierce dan Ljung Box.Untuk kedua uji yang terakhir ini mensyaratkan bahwa data observasi di atas 100 sampel dan derajat autokorelasi lebih dari satu.
Korelasi peringkat.
Terdapat tiga jenis koefisien korelasi peringkat pada
nonparametrik yang umumnya digunakan yaitu Spearman R, Kendal tau dan Gamma Coefficient.
Statistik chi-square juga
merupakan bagian dari korelasi non-parametrik, tetapi berbeda dengan ketiga
jenis korelasi tersebut, perhitungannya didasarkan pada tabel frekuensi dua
arah (tabel silang). Selain itu, dalam Spearman R, Kendal tau dan Gamma
mempersyaratkan data dalam skala ordinal (atau dapat diordinal/di peringkat),
sedangkan pada statistik chi-square dapat berupa data nominal maupun ordinal.
Untuk statistik chi-square akan dibahas pada seri tulisan
mengenai non-parametrik berikutnya Spearman R adalah ukuran korelasi pada
statistik non-parametrik yang analog dengan koefisien korelasi Pearson Product
Moment pada statistik parametrik. Spearman R adalah korelasi Pearson yang
dihitung atas dasar rank dari data.
Kendal tau, adalah ukuran korelasi yang setara dengan
Spearman R, terkait dengan asumsi yang mendasarinya serta kekuatan
statistiknya. Namun, besaran Spearman R dan Kendal tau akan berbeda karena
perbedaan dalam logika mendasari serta formula perhitungannya.
Jika Spearman R setara dengan koefisien korelasi Pearson
Product Moment, yaitu koefisien korelasinya pada dasarnya menunjukkan proporsi
variabilitas (dimana untuk Spearman R dihitung dari ranks sedangkan korelasi
Pearson dari data aslinya), sebaliknya ukuran Kendal tau merupakan probabilita
perbedaan antara probabilita data dua variabel dalam urutan yang sama dengan
probabilita dua variabel dalam urutan yang berbeda.
Berdasarkan logika perhitungan ini, Noether
(1981) dalam (Daniel,1991) mengemukakan bahwa koefisien Kendal
tau lebih mudah ditafsirkan dibandingkan Spearman R. Gamma statistic,
lebih baik dibandingkan Spearman R atau Kendal tau ketika data mengandung
banyak observasi yang memiliki nilai yang sama.
Gamma ekuivalen dengan Spearman R dan Kendal tau dari
sisi asumsi yang mendasarinya. Tetapi dari sisi intepretasi dan perhitungannya,
Gamma lebih mirip dengan Kendal tau.
Secara sederhana, untuk melihat efektivitas iklan
terhadap penjualan, akan dilihat korelasi dari kedua variabel tersebut. Jika
terdapat korelasi positif yang signifikan, maka dapat disimpulkan iklan
tersebut efektif dalam meningkatkan penjualan. Demikian juga sebaliknya.
Untuk menghitung koefisien korelasi untuk ketiga
pengukuran (tersebut, langkah pertama yang dilakukan adalah dengan memberi
rangking untuk iklan dan penjualan, mulai dari yang angka terkecil sampai angka
terbesar.
Model-Model Analisis Statistik Non-Parametrik
Statistik nonparametrik adalah valid dengan asumsi yang longgar serta teorinya relatif luwes. Karenanya metode ini relatif serba bisa/serba guna, memiliki banyak alternatif prosedur dan diaplikasikan dalam banyak metode-metode analisis baru.
Model-Model Analisis Statistik Non-Parametrik
Statistik nonparametrik adalah valid dengan asumsi yang longgar serta teorinya relatif luwes. Karenanya metode ini relatif serba bisa/serba guna, memiliki banyak alternatif prosedur dan diaplikasikan dalam banyak metode-metode analisis baru.
Mengingat banyaknya alternatif prosedur statistik
non-parametrik menyebabkan berbagai literatur memberikan pengelompokan kategori
statistik non parametrik dengan berbagai cara yang berbeda. Namun demikian,
secara sederhana dan berdasarkan prosedur yang sering digunakan, uji-uji
tersebut diantaranya dapat dikelompokkan atas kategori berikut: statistik
nonparametrik adalah valid dengan asumsi yang longgar serta teorinya relatif
luwes. Karenanya metode ini relatif serba bisa/serba guna, memiliki banyak
alternatif prosedur dan diaplikasikan dalam banyak metode-metode analisis baru.
Mengingat banyaknya alternatif prosedur statistik
non-parametrik menyebabkan berbagai literatur memberikan pengelompokan kategori
statistik non parametrik dengan berbagai cara yang berbeda. Namun demikian,
secara sederhana dan berdasarkan prosedur yang sering digunakan, uji-uji
tersebut diantaranya dapat dikelompokkan atas kategori berikut:
• Prosedur untuk data dari sampel tunggal
• Prosedur untuk data dari dua kelompok atau lebih sampel bebas (independent)
• Prosedur untuk data dari dua kelompok atau lebih sampel berhubungan (dependent)
• Korelasi peringkat dan ukuran-ukuran asosiasi lainnya
• Prosedur untuk data dari sampel tunggal
• Prosedur untuk data dari dua kelompok atau lebih sampel bebas (independent)
• Prosedur untuk data dari dua kelompok atau lebih sampel berhubungan (dependent)
• Korelasi peringkat dan ukuran-ukuran asosiasi lainnya
1.Prosedur untuk data dari sampel tunggal
Prosedur bertujuan untuk menduga dan menguji hipotesis parameter populasi seperti ukuran nilai sentral. Dalam statistik parametrik, ukuran nilai sentral yang umum adalah rata-rata dan median, dan pengujian hipotesisnya menggunakan uji t. Namun demikian, uji t memiliki asumis bahwa populasi dari sampel yang diambil berdistribusi normal. Jika asumsi ini tidak terpenuhi, akan mempengaruhi kesimpulan pengujian hipotesis.
Prosedur bertujuan untuk menduga dan menguji hipotesis parameter populasi seperti ukuran nilai sentral. Dalam statistik parametrik, ukuran nilai sentral yang umum adalah rata-rata dan median, dan pengujian hipotesisnya menggunakan uji t. Namun demikian, uji t memiliki asumis bahwa populasi dari sampel yang diambil berdistribusi normal. Jika asumsi ini tidak terpenuhi, akan mempengaruhi kesimpulan pengujian hipotesis.
Prosedur non parametrik untuk menduga nilai sentral untuk
sampel tunggal ini diantaranya adalah uji tanda untuk sampel tunggal dan uji
peringkat bertanda Wilcoxon. Selain pengukuran tendensi sentral, juga terdapat
prosedur non parametrik lainnya untuk sampel tunggal dalam pengukuran proporsi
populasi (yaitu uji binomial) dan uji kecenderungan (trend) data berdasarkan
waktu (yaitu uji Cox-Stuart)
2. Prosedur untuk sampel independen.
Prosedur ini digunakan ketika kita ingin membandingkan dua variabel yang diukur dari sampel yang tidak sama (bebas). Misalnya sampel yang diambil berasal dari dua populasi yaitu populasi rumah pedagang sate dan populasi pedagang bakso, dan ingin membandingkan rata-rata pendapatan diantara kedua kelompok pedagang ini.
Dalam statistik parametrik, untuk membandingkan membandingkan nilai rata-rata dua kelompok independent, dapat digunakan uji t (t-test). Untuk nonparametrik, alternatif pengujiannya diantaranya adalah Wald-Wolfowitz runs test, Mann-Whitney U test dan Kolmogorov-Smirnov two-sample test. Selanjutnya, jika kelompok yang diperbandingkan lebih dari dua, dalam statistik parametrik dapat menggunakan analisis varians (ANOVA/MANOVA), dan pada statistik nonparametrik alternatifnya diantaranya adalah analisis varians satu arah berdasarkan peringkat Kruskal-Wallis dan Median test.
Prosedur ini digunakan ketika kita ingin membandingkan dua variabel yang diukur dari sampel yang tidak sama (bebas). Misalnya sampel yang diambil berasal dari dua populasi yaitu populasi rumah pedagang sate dan populasi pedagang bakso, dan ingin membandingkan rata-rata pendapatan diantara kedua kelompok pedagang ini.
Dalam statistik parametrik, untuk membandingkan membandingkan nilai rata-rata dua kelompok independent, dapat digunakan uji t (t-test). Untuk nonparametrik, alternatif pengujiannya diantaranya adalah Wald-Wolfowitz runs test, Mann-Whitney U test dan Kolmogorov-Smirnov two-sample test. Selanjutnya, jika kelompok yang diperbandingkan lebih dari dua, dalam statistik parametrik dapat menggunakan analisis varians (ANOVA/MANOVA), dan pada statistik nonparametrik alternatifnya diantaranya adalah analisis varians satu arah berdasarkan peringkat Kruskal-Wallis dan Median test.
3. Prosedur untuk Sampel dependen.
Prosedur ini digunakan ketika ingin membandingkan dua variabel yang diukur dari sampel sama (berhubungan). Misalnya ingin mengetahui perbedaan produktivitas kerja, dengan pengukuran dilakukan pada sampel pekerja yang sama baik sebelum maupun sesudah pelatihan dilakukan.
Prosedur ini digunakan ketika ingin membandingkan dua variabel yang diukur dari sampel sama (berhubungan). Misalnya ingin mengetahui perbedaan produktivitas kerja, dengan pengukuran dilakukan pada sampel pekerja yang sama baik sebelum maupun sesudah pelatihan dilakukan.
Pada statistik parametrik, jika ingin membandingkan dua
variabel yang diukur dalam sampel yang sama, dapat menggunakan uji t data
berpasangan. Sebaliknya, alternatif non-parametrik untuk uji ini adalah Sign
test dan Wilcoxon’s matched pairs test. Jika variabel diteliti bersifat
dikotomi, dapat menggunakan McNemar’s Chi-Square test. Selanjutnya, jika
terdapat lebih dari dua variabel, dalam statistik parametrik, dapat menggunakan
ANOVA. Alternatif nonparametrik untuk metode ini adalah Friedman’s two-way
analysis of variance dan Cochran Q test.
4. Korelasi Peringkat dan Ukuran-Ukuran
Asosiasi Lainnya.
Dalam statistik parametrik ukuran korelasi yang umum digunakan adalah korelasi Product Moment Pearson. Diantara korelasi nonparametrik yang ekuivalen dengan koefisien korelasi standar ini dan umum digunakan adalah Spearman R, Kendal Tau dan coefficien Gamma. Selain ketiga pengukuran tersebut, Chi square yang berbasiskan tabel silang juga relatif populer digunakan dalam mengukur korelasi antar variabel.
Dalam statistik parametrik ukuran korelasi yang umum digunakan adalah korelasi Product Moment Pearson. Diantara korelasi nonparametrik yang ekuivalen dengan koefisien korelasi standar ini dan umum digunakan adalah Spearman R, Kendal Tau dan coefficien Gamma. Selain ketiga pengukuran tersebut, Chi square yang berbasiskan tabel silang juga relatif populer digunakan dalam mengukur korelasi antar variabel.
Statistik Uji Kruskal-Wallis
Bagian ini akan membahas mengenai Statistik Uji Kruskal-Wallis, contoh perhitungan manualnya dan aplikasi pada program statistik SPSS.
Analisis varians satu arah berdasarkan peringkat Kruskal-Wallis pada statistik non-parametrik dapat digunakan pada sampel independent dengan kelompok lebih dari dua.
Korelasi Peringkat
Bagian ini akan membahas mengenai korelasi peringkat. Terdapat tiga jenis koefisien korelasi peringkat pada nonparametrik yang umumnya digunakan yaitu Spearman R, Kendal tau dan Gamma Coefficient. Statistik chi-square juga merupakan bagian dari korelasi non-parametrik, tetapi berbeda dengan ketiga jenis korelasi tersebut,
Bagian ini akan membahas mengenai Statistik Uji Kruskal-Wallis, contoh perhitungan manualnya dan aplikasi pada program statistik SPSS.
Analisis varians satu arah berdasarkan peringkat Kruskal-Wallis pada statistik non-parametrik dapat digunakan pada sampel independent dengan kelompok lebih dari dua.
Korelasi Peringkat
Bagian ini akan membahas mengenai korelasi peringkat. Terdapat tiga jenis koefisien korelasi peringkat pada nonparametrik yang umumnya digunakan yaitu Spearman R, Kendal tau dan Gamma Coefficient. Statistik chi-square juga merupakan bagian dari korelasi non-parametrik, tetapi berbeda dengan ketiga jenis korelasi tersebut,
Korelasi Peringkat dengan SPSS
Tulisan ini merupakan lanjutan dari tulisan seri 4 non-parametrik yang membahas mengenai korelasi peringkat pada statistik non-parametrik. Jika pada tulisan sebelumnya diberikan pengertian dasar dan contoh perhitungan secara manual, maka pada bagian ini akan diberikan aplikasi perhitungannya menggunakan paket program statistik SPSS
Tulisan ini merupakan lanjutan dari tulisan seri 4 non-parametrik yang membahas mengenai korelasi peringkat pada statistik non-parametrik. Jika pada tulisan sebelumnya diberikan pengertian dasar dan contoh perhitungan secara manual, maka pada bagian ini akan diberikan aplikasi perhitungannya menggunakan paket program statistik SPSS
PERTEMUAN KE-12
Independent Sample T-test
Pengertian
dan contoh uji data Independent Sample
T-test serta langkah-langkah menganalisisnya menggunakan SPSS
Independent sample t test merupakan uji yang digunakan untuk membandingkan dua sampel data yang tidak terkait atau bebas.
contoh uji Independent Sample T test yaitu sebagai berikut :
Pada
2 buah kelas pembelajaran IPA, diterapkan multimedia interaktif pada kelas 9A
(kelas eksperimen) dan media gambar pada kelas 9B (kelas kontrol), kemudian
dilakukan test untuk mengetahui apakah penggunaan multimedia interaktif lebih
baik dibandingkan dengan media gambar dilihat dari nilai rata-rata hasil
belajar IPA siswa. Kasus ini akan dilakukan analisis dengan menggunakan
uji Independent sample t test.Adapun hipotesis yang digunakan dalam
penelitian ini adalah :
·
Hipotesis
1: rata-rata hasi belajar IPA menggunakan multimedia interaktif lebih besar di
bandingkan dengan menggunakan media gambar.
·
Ho :
Hasil B = Hasil B
·
H1 : Hasil B > Hasil A
Data
yang digunakan yaitu :
|
Hasil Belajar
|
Group
|
Hasil Belajar
|
Group
|
|
|
70
|
1
|
70
|
2
|
|
|
80
|
1
|
80
|
2
|
|
|
90
|
1
|
65
|
2
|
|
|
60
|
1
|
70
|
2
|
|
|
70
|
1
|
80
|
2
|
|
|
80
|
1
|
90
|
2
|
|
|
90
|
1
|
70
|
2
|
|
|
90
|
1
|
60
|
2
|
|
|
80
|
1
|
75
|
2
|
|
|
70
|
1
|
60
|
2
|
|
|
60
|
1
|
70
|
2
|
|
|
70
|
1
|
80
|
2
|
|
|
80
|
1
|
80
|
2
|
|
|
90
|
1
|
80
|
2
|
|
|
70
|
1
|
80
|
2
|
|
|
60
|
1
|
90
|
2
|
|
|
70
|
1
|
70
|
2
|
|
|
80
|
1
|
85
|
2
|
|
|
80
|
1
|
80
|
2
|
|
|
80
|
1
|
70
|
2
|
|
|
90
|
1
|
75
|
2
|
|
|
70
|
1
|
80
|
2
|
|
|
60
|
1
|
70
|
2
|
|
|
80
|
1
|
90
|
2
|
Langkah-langkah
untuk menyelesaikan kasus tersebut yaitu sebagai berikut :
1. Membuka SPSS,kemudian mengisi pada
variabel View seperti di bawah ini :

Pada values kolom Group
diisi dengan Media Gambar dan Multimedia,caranya yaitu dengan mengeklik
tombol Add setelah Value dan Label diisi,lalu Klik Ok.

2. Mengisi Measure pada kolom pertama dengan
Scale dan kolom kedua dengan Nominal

3. Membuka data view lalu mengisi dengan
nilai pada kolom Hasil_Belajar dan Group

4. dengan cara klik Analyze >>
Nonparametric tests >> Legacy Dialog >> 1-Simple K-S

Pada group ini
tidak memerlukan uji normalitas,yang di uji normalitas adalah Hasil
Belajar,sehingga Group tidak dipindahkan ke ruas sebelah kanan

Hasil yang diperoleh
yaitu sebagai berikut :

Karena hasil Asymp Sig
(2-tailed) 0,50 >0,05 maka data tersebut normal. Setelah data diketahui
normal maka selanjutnya menganalisis Independent Sample T
test.Langkahnya yaitu sebagai berikut :
1. Klik Analyze >> Compare Means >> lalu
pilih Independent Sample T test.

2. Memindahkan Hasil Belajar pada Test
Variable(s) dan Group pada Grouping Variable

3. Pada Group terdapat
tanda tanya,kemudian kilik Define Groups lalu isi dengan gruop1
dan 2 >> Continue >> Ok.

Hasil
yang diperoleh yaitu sebagai berikut :

Kesimpulan :
Karena
Sig 0,230 > 0,05 maka H0 Diterima dan H1 ditolak,maka kesimpulannya tidak
ada perbedaan antara rata-rata hasil belajar IPA menggunakan
multimedia interaktif dan dengan menggunkaan media gambar.
PERTEMUAN KE-13
UTS
PERTEMUAN KE-14
UAS
diposting oleh Dr. Siswantoro, S.Sos, M.M. @ 18.55
0 Komentar
![]()

